
When I started working with machine learning problems, I panicked about which algorithm I should use. Or which one is easy to apply? If you are like me, this article might help you know about artificial intelligence and machine learning algorithms, methods, or techniques to solve any unexpected or expected problems.
Machine learning is a powerful AI technique that can perform a task effectively without explicit instructions. An ML model can learn from its data and experience. Machine learning applications are automatic, robust, and dynamic. Several algorithms have been developed to address this dynamic nature of real-life problems. Broadly, there are three types of machine learning algorithms: supervised learning, unsupervised learning, and reinforcement learning.
Best AI & Machine Learning Algorithms
Selecting the appropriate machine learning technique or method is one of the main tasks in developing an artificial intelligence or machine learning project. Because there are several algorithms available, and all of them have their benefits and utility. Below we are narrating 20 machine learning algorithms for both beginners and professionals. So, let’s take a look.
1. Naive Bayes
A Naïve Bayes classifier is a probabilistic classifier based on the Bayes theorem, with the assumption of independence between features. These features differ from application to application. It is one of the most comfortable machine learning methods for beginners to practice.
Naïve Bayes is a conditional probability model. Given a problem instance to be classified, represented by a vector x = (xi . . . xn) representing some n features (independent variables), it assigns to the current instance probabilities for every of K potential outcomes:
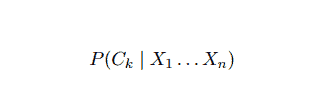 The problem with the above formulation is that if the number of features n is significant or if an element can take on a large number of values, then basing such a model on probability tables is infeasible. We, therefore, redevelop the model to make it more tractable. Using Bayes’ theorem, the conditional probability may be written as,
The problem with the above formulation is that if the number of features n is significant or if an element can take on a large number of values, then basing such a model on probability tables is infeasible. We, therefore, redevelop the model to make it more tractable. Using Bayes’ theorem, the conditional probability may be written as,
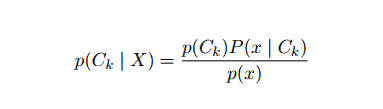
Using Bayesian probability terminology, the above equation can be written as:
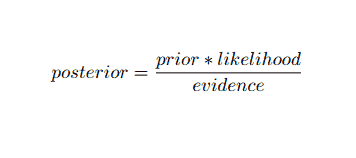
This artificial intelligence algorithm is used in text classification, i.e., sentiment analysis, document categorization, spam filtering, and news classification. This machine learning technique performs well if the input data are categorized into predefined groups. Also, it requires less data than logistic regression. It outperforms in various domains.
2. Support Vector Machine
Support Vector Machine (SVM) is one of the most extensively used supervised machine learning algorithms in the field of text classification. This method is also used for regression. It can also be referred to as Support Vector Networks.
Cortes & Vapnik developed this method for binary classification. The supervised learning model is the machine learning approach that infers the output from the labeled training data.
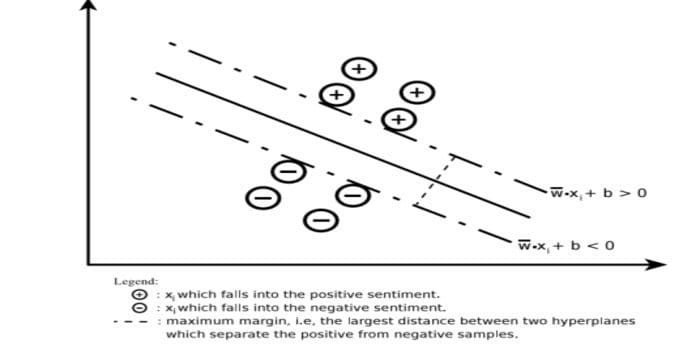
A support vector machine constructs a hyperplane or set of hyperplanes in a very high or infinite-dimensional area. It computes the linear separation surface with a maximum margin for a given training set.
Only a subset of the input vectors will influence the choice of the margin (circled in the figure); such vectors are called support vectors. When a linear separation surface does not exist, for example, in the presence of noisy data, SVMs algorithms with a slack variable are appropriate. This Classifier attempts to partition the data space with the use of linear or non-linear delineations between the different classes.
SVM has been widely used in pattern classification problems and nonlinear regression. Also, it is one of the best techniques for performing automatic text categorization. The best thing about this algorithm is that it does not make any strong assumptions about data.
To implement Support Vector Machine: Data Science Libraries in Python– SciKit Learn, PyML, SVMStruct Python, LIBSVM, and Data Science Libraries in R– Klar, e1071.
3. Linear Regression
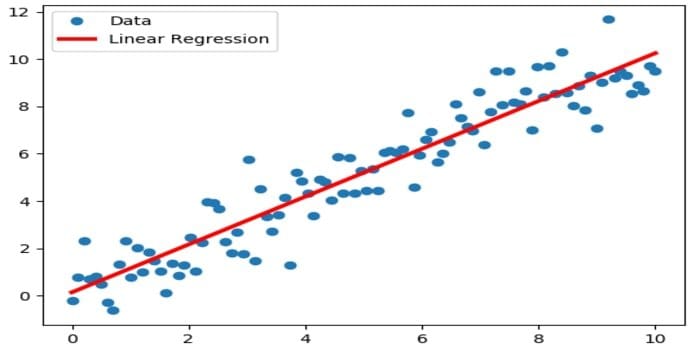
Linear regression is a direct approach that is used to modeling the relationship between a dependent variable and one or more independent variables. If there is one independent variable, then it is called simple linear regression. If more than one independent variable is available, then this is called multiple linear regression.
This formula is employed to estimate real values like the price of homes, number of calls, and total sales based on continuous variables. Here, the relationship between independent and dependent variables is established by fitting the best line. This best fit line is known as a regression line and is represented by a linear equation
Y= a *X + b.
here,
- Y – dependent variable
- a – slope
- X – independent variable
- b – intercept
This machine learning method is easy to use. It executes fast. This can be used in business for sales forecasting. It can also be used in risk assessment.
4. Logistic Regression
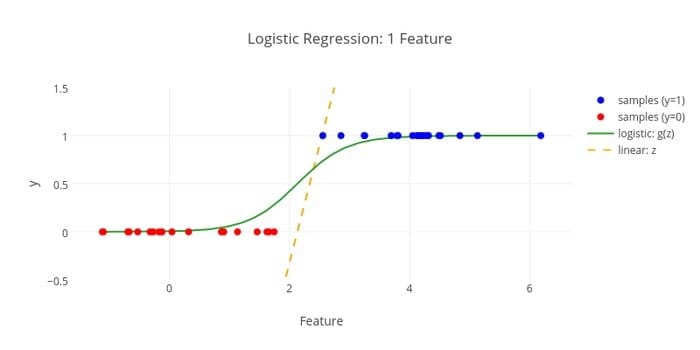
Here is another machine learning algorithm – Logistic regression or logit regression- used to estimate discrete values (Binary values like 0/1, yes/no, true/false) based on a given set of independent variables. This algorithm’s task is to predict an incident’s probability by fitting data to a logit function. Its output values lie between 0 and 1.
The formula can be used in various areas like machine learning, scientific discipline, and medical fields. It can be used to predict the danger of occurring a given disease based on the observed characteristics of the patient.
Logistic regression can be utilized for the prediction of a customer’s desire to buy a product. This machine learning technique is used in weather forecasting to predict the probability of rain.
Logistic regression can be divided into three types –
- Binary Logistic Regression
- Multi-nominal Logistic Regression
- Ordinal Logistic Regression
Logistic regression is less complicated. Also, it is robust. It can handle non-linear effects. However, this ML algorithm may overfit if the training data is sparse and high dimensional. It cannot predict continuous outcomes.
5. K-Nearest-Neighbor (KNN)
K-nearest-neighbor (kNN) is a well-known statistical approach for classification and has been widely studied over the years and applied early to categorization tasks. It acts as a non-parametric methodology for classification and regression problems.
This AI and ML method is quite simple. It determines the category of a test document t based on voting a set of k documents nearest to t in terms of distance, usually Euclidean distance. The essential decision rule given a testing document t for the kNN classifier is:
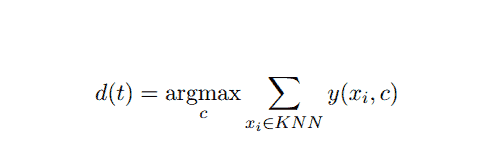
Where y (xi,c ) is a binary classification function for training document xi (which returns value 1 if xi is labeled with c, or 0 otherwise), this rule labels with t with the category that is given the most votes in the k-nearest neighborhood.
We can be mapped KNN to our real lives. For example, if you would like to find out a few people of whom you have no info, you would prefer to decide regarding his close friends and, therefore, the circles he moves in and gains access to his/her information. This algorithm is computationally expensive.
6. K-means
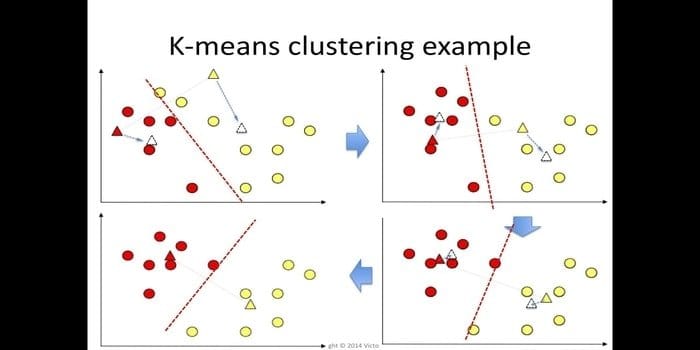
k-means clustering is a method of unsupervised learning which is accessible for cluster analysis in data mining. This algorithm aims to divide n observations into k clusters where every observation belongs to the closest mean of the cluster. This algorithm is used in market segmentation, computer vision, and astronomy, among many other domains.
7. Decision Tree
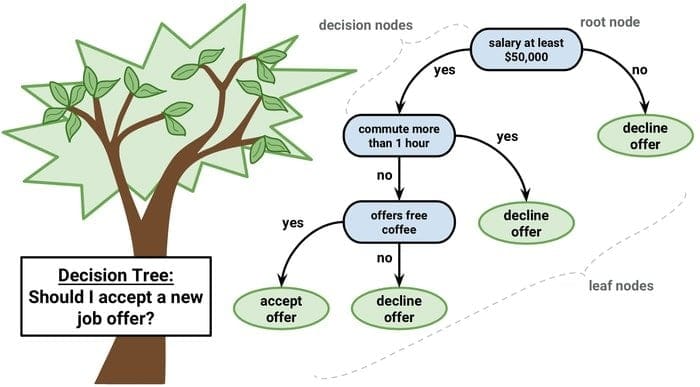
A decision tree is a decision support tool that uses a graphical representation, i.e., a tree-like graph or model of decisions. It is commonly used in decision analysis and is also a popular tool in machine learning. Decision trees are used in operations research and operations management.
It has a flowchart-like structure in which every internal node represents a ‘test’ on an attribute, every branch represents the outcome of the test, and each leaf node represents a class label. The route from the root to the leaf is known as classification rules. It consists of three types of nodes:
- Decision nodes: typically represented by squares,
- Chance nodes: usually represented by circles,
- End nodes: usually represented by triangles.
A decision tree is simple to understand and interpret. It uses a white-box model. Also, it can combine with other decision techniques.
8. Random Forest
Random forest is a popular technique of ensemble learning which operates by constructing a multitude of decision trees at training time and output the category, that’s the mode of the categories (classification) or mean prediction (regression) of each tree.
The runtime of this machine learning algorithm is fast, and it can able to work with unbalanced and missing data. However, when we used it for regression, it could not predict beyond the range in the training data, and it may overfit data.
9. CART
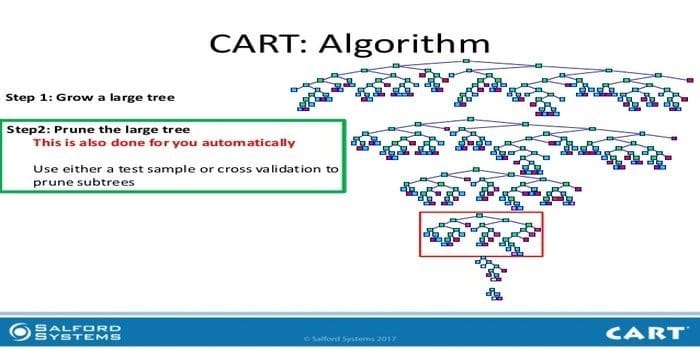
Classification and Regression Tree (CART) is one kind of decision tree. A Decision Tree is working as a recursive partitioning approach, and CART divides each of the input nodes into two child nodes. At each level of a decision tree, the algorithm identifies a condition – which variable and level to be used for splitting the input node into two child nodes.
CART algorithm steps are given below:
- Take Input data
- Best Split
- Best Variable
- Split the input data into left and right nodes
- Continue steps 2-4
- Decision Tree Pruning
10. Apriori Machine Learning Algorithm

The Apriori algorithm is a categorization algorithm. This machine learning technique is used for sorting large amounts of data. It can also be used to follow up on how relationships develop and categories are built. This algorithm is an unsupervised learning method that generates association rules from a given data set.
Apriori Machine Learning Algorithm works as:
- If an item set occurs frequently, then all the subsets of the item set also happen often.
- If an item set occurs infrequently, then all the supersets of the item set also have infrequent occurrences.
This ML algorithm is used in a variety of applications, such as to detect adverse drug reactions, market basket analysis, and auto-complete applications. It’s straightforward to implement.
11. Principal Component Analysis (PCA)
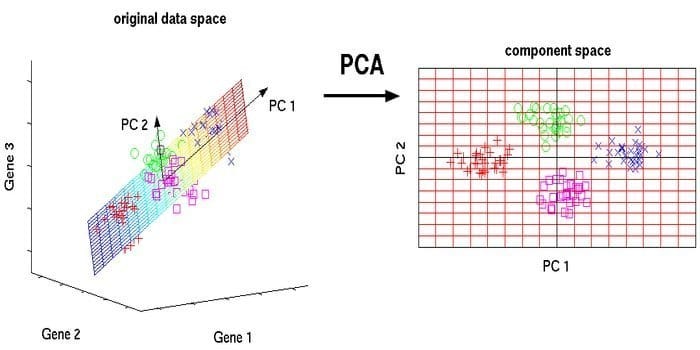
Principal component analysis (PCA) is an unsupervised algorithm. The new features are orthogonal, which means they are not correlated. Before performing PCA, you should always normalize your dataset because the transformation is dependent on scale. If you do not, the features that are on the most significant scale will dominate new principal components.
PCA is a versatile technique. This algorithm is effortless and simple to implement. It can be used in image processing.
12. CatBoost

CatBoost is an open-sourced machine learning algorithm that comes from Yandex. The name ‘CatBoost’ comes from two words, ‘ Category’ and ‘Boosting.’ It can combine with deep learning frameworks, i.e., Google’s TensorFlow and Apple’s Core ML. CatBoost can work with numerous data types to solve several problems.
13. Iterative Dichotomiser 3 (ID3)

Iterative Dichotomiser 3(ID3) is a decision tree learning algorithmic rule presented by Ross Quinlan that is employed to supply a decision tree from a dataset. It is the precursor to the C4.5 algorithmic program and is employed within the machine learning and linguistic communication domains.
ID3 may overfit the training data. This algorithmic rule is tougher to use on continuous data. It does not guarantee an optimal solution.
14. Hierarchical Clustering
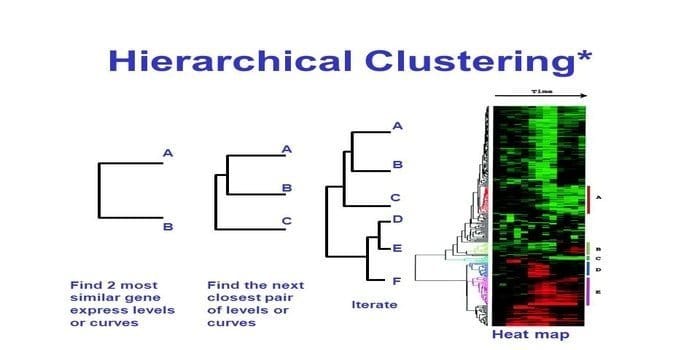
Hierarchical clustering is a way of cluster analysis. A cluster tree (a dendrogram) is developed in hierarchical clustering to illustrate data. In hierarchical clustering, each group (node) links to two or more successor groups. Each node within the cluster tree contains similar data. Nodes group on the graph next to other similar nodes.
Algorithm
This machine learning method can be divided into two models – bottom up or top down:
Bottom-up (Hierarchical Agglomerative Clustering, HAC)
- At the beginning of this machine learning technique, take each document as a single cluster.
- In a new cluster, merge two items at a time. How the combines merge involves calculating a difference between every incorporated pair and, therefore, the alternative samples. There are many options to do this. Some of them are:
a. Complete linkage: Similarity of the furthest pair. One limitation is that outliers might cause the merging of close groups later than is optimal.
b. Single-linkage: The similarity of the closest pair. It may cause premature merging, though those groups are quite different.
c. Group average: similarity between groups.
d. Centroid similarity: each iteration merges the clusters with the foremost similar central point.
- The pairing process is going on until all items merge into a single cluster.
Top down (Divisive Clustering)
- Data starts with a combined cluster.
- The cluster divides into two distinct parts according to some degree of similarity.
- Clusters divide into two again and again until the clusters only contain a single data point.
15. Back-Propagation
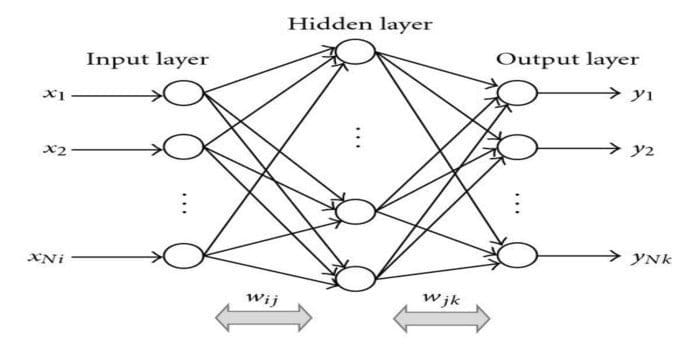
Back-propagation is a supervised learning algorithm. This ML algorithm comes from the area of ANN (Artificial Neural Networks). This network is a multilayer feed-forward network. This technique aims to design a given function by modifying the internal weights of input signals to produce the desired output signal. It can be used for classification and regression.

Back-propagation algorithm has some advantages, i.e., it’s easy to implement. The mathematical formula used in the algorithm can be applied to any network. Computation time may be reduced if the weights are small.
Back-propagation algorithm has some drawbacks, such as being sensitive to noisy data and outliers. It is an entirely matrix-based approach. The actual performance of this algorithm entirely depends on input data. The output may be non-numeric.
16. AdaBoost

AdaBoost means Adaptive Boosting, a machine learning method represented by Yoav Freund and Robert Schapire. It is a meta-algorithm that can be integrated with other learning algorithms to enhance performance. This algorithm is quick and easy to use. It works well with large data sets.
17. Deep Learning

Deep learning is a set of techniques inspired by the mechanism of the human brain. The two primary deep learning, i.e., Convolution Neural Networks (CNN) and Recurrent Neural Networks (RNN), are used in text classification.
Deep learning algorithms like Word2Vec or GloVe are also employed to get high-ranking vector representations of words and improve the accuracy of classifiers that are trained with traditional machine learning algorithms.
This machine learning method needs a lot of training samples instead of traditional machine learning algorithms, i.e., a minimum of millions of labeled examples. On the opposite hand, traditional machine learning techniques reach a precise threshold wherever adding more training samples does not improve their accuracy overall. Deep learning classifiers outperform better results with more data.
18. Gradient Boosting Algorithm

Gradient boosting is a machine learning method that is used for classification and regression. It is one of the most powerful ways of developing a predictive model. A gradient boosting algorithm has three elements:
- Loss Function
- Weak Learner
- Additive Model
19. Hopfield Network

A Hopfield network is one kind of recurrent artificial neural network given by John Hopfield in 1982. This network aims to store one or more patterns and recall the full patterns based on partial input. In a Hopfield network, all the nodes are both inputs and outputs and fully interconnected.
20. C4.5

C4.5 is a decision tree which is invented by Ross Quinlan. It’s an upgrade version of ID3. This algorithmic program encompasses a few base cases:
- All the samples in the list belong to a similar category. It creates a leaf node for the decision tree, saying to decide on that category.
- It creates a decision node higher up the tree using the expected value of the class.
- It creates a decision node higher up the tree using the expected value.
Ending Thoughts
It’s very much essential to use the proper algorithm based on your data and domain to develop an efficient machine learning project. Also, understanding the critical difference between every machine learning algorithm is essential to address ‘when I pick which one.’
As in a machine learning approach, a machine or device has learned through the learning algorithm. I firmly believe that this article helps you to understand the algorithm. If you have any suggestions or queries, please feel free to ask. Keep reading.

{kind=link}
Is genetic programming used in any recent AI applications?
It is built using a mathematical model and has data pertaining to both the input and the output. For instance, if the goal is to find out whether a certain image contained a train, then different images with and without a train will be labeled and fed in as training data.
So, basically, you have the inputs ‘A’ and the Output ‘Z’. Supervised learning uses a function to map the input to get the desired output.
Z=f(A)