


In modern times, speech is a popular and smart method for interacting with electronic devices. As we know, there are many open source speech recognition tools available on different platforms. From the beginning of this technology, understanding the human voice has improved simultaneously. This is why it has engaged many more professionals than before. The technical advancement is strong enough to make it clearer to the common people.
Open-source Speech Recognition Tools for Linux
Open source voice recognition tools are not available like the typical software we use in our daily lives on the Linux platform. After a long research, we found some well-featured applications for you with a short description. Let’s have a look at the points below!
1. Kaldi
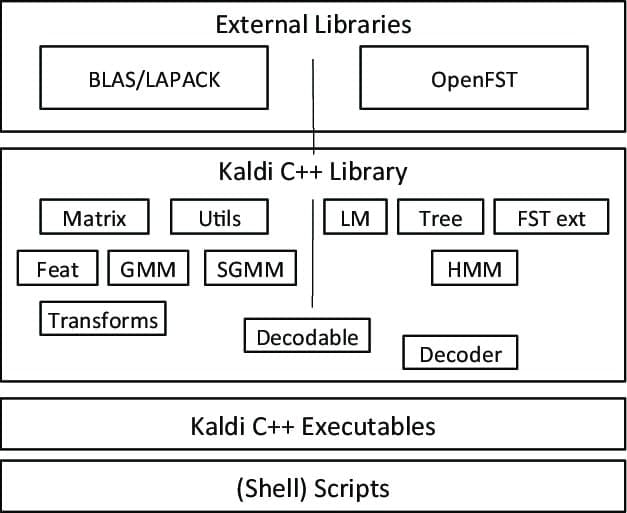
Kaldi is a special kind of speech recognition software that was started as a part of a project at John Hopkins University. This toolkit comes with an extensible design and is written in C++ programming language. It provides a flexible and comfortable environment to its users, with a lot of extensions to enhance Kaldi’s power.

Noteworthy Features
- A free and flexible open source voice recognition application under the Apache license.
- Runs on multiple platforms, including GNU/Linux, BSD, and Microsoft Windows.
- Provides support in installing and configuring the application for your system.
- Besides the speech recognition system, it also supports deep neural networks and linear transforms.
2. CMUSphinx
CMUSphinx comes with a group of featured-enriched systems with several pre-built packages related to speech recognition. It is an open-source program developed at Carnegie Mellon University. You will get this speaker-independent recognition tool in several languages, including French, English, German, and Dutch.


Noteworthy Features
- It is an easy-to-use and fast speech recognition system with a user-friendly interface.
- Comes with a flexible design and efficient system, even in low-resource platforms.
- Provides acoustic model training tools through its Sphinxtrain package.
- Helps to perform different types of tasks through its helpful packages, including keyword spotting, pronunciation evaluation, alignment, and more.
- It is a cross-platform tool that supports both Windows and Linux systems.
3. DeepSpeech
DeepSpeech is an open source speech recognition engine that converts your speech to text. It is a free application by Mozilla. To run the DeepSearch project on your device, you will need Python 3 or above. Also, it needs a Git extension file, namely Git Large File Storage. It is used to version large files while you run them on your system.
Noteworthy Features
- DeepSpeech uses the TensorFlow framework to make the voice transformation more comfortable.
- It supports NVIDIA GPU, which helps to perform quicker inference.
- You can use the DeepSearch inference in three ways: The Python package, the Node.JS package, or the Command-line client.
- Each time you want to run this software on your system, you’ll need to activate the virtual environment using the Python command.
- This application needs a Linux or Mac environment to run.
4. Wav2Letter++
WavLetter++ is a modern and popular speech recognition tool developed by the Facebook AI Research team. It is another open source program under the BCD license. This superfast voice recognition software was built in C++ and introduced with a lot of features. It provides the facility of language modeling, machine translation, speech synthesis, and more to its users in a flexible environment.
Noteworthy Features
- It contains an active community on popular platforms like Facebook and Google groups to assist its users worldwide.
- WavLetter++ is a fast and flexible toolkit that uses the ArrayFire tensor library for maximum efficiency.
- It lets you work with a high-performance framework like wav2letter++, which helps to do successful research and model tuning.
- Also, it provides complete documentation through the tutorial sections.
- You will find detailed recipes for WSJ, Timit, and Librispeech in the recipes folder.
5. Julius
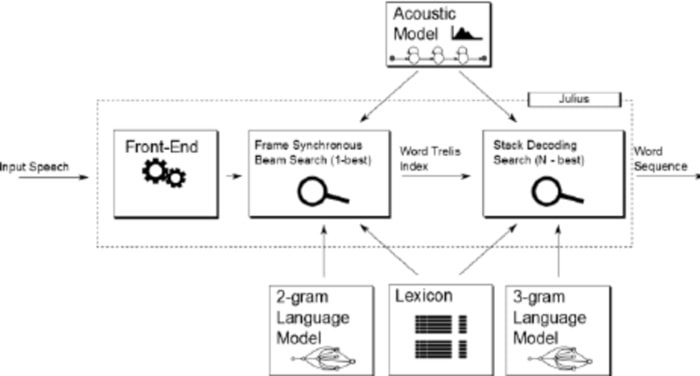
Julius is comparatively an older open source voice recognition software developed by Lee Akinobu. This tool is written in the C programming language by the developers of Kawahara Lab, Kyoto University. It is a high-performance speech recognition application with a large vocabulary. You can use it in both English and Japanese languages. It can be a great choice if you want to use it for academic and research purposes.

Noteworthy Features
- Julius is a highly configurable application that can set different search parameters to tune its performance.
- This tool is based on a 2-pass strategy, which provides you with real-time and high-quality performance.
- It is a cross-platform project that runs on Linux, BSD, Windows, and Android Systems.
- Integrated with Julian, a grammar-based recognition parser.
- Besides supporting rule-based grammar, it provides Word graph output, Confidence scoring, GMM-based input rejection, and many more facilities.
6. Simon
Simon comes with a modern and easy-to-use speech recognition software developed by Peter Grasch. It is another open source program under the GNU General Public License. You are free to use Simon in both Linux and Windows systems. Also, it provides the flexibility to work with any language you want.

Noteworthy Features
- Simon provides the facility to do various arithmetic operations using its voice-controlled calculator.
- Compatible with Skype and other popular VOIP programs to establish an easy communication system with friends and relatives.
- It allows users to watch slide shows and videos, listen to music, and more with simple voice commands.
- Also, it is an essential tool for reading newspapers and surfing the internet.
7. Mycroft
Mycroft has an easy-to-use open source voice assistant that converts voice to text. It is regarded as one of the most popular Linux speech recognition tools in modern times, written in Python. It allows users to make the best use of this tool in a science project or enterprise software application. Also, it can be used as a practical assistant that can tell you the time, date, weather, and more.
Noteworthy Features
- Integrated with the most popular social media and professional platforms, including Facebook, Github, LinkedIn, and more.
- You can run this application on different software and hardware platforms. It can be a desktop or a Raspberry Pi.
- Besides being a smart voice assistant, it provides the facility of audio recording, machine learning, software library, and more.
- It lets users convert the natural language to machine-readable data through Adapt, an intent parser of Mycroft.
8. OpenMindSpeech
OpenMindSpeech is one of the essential Linux speech recognition tools that aims to convert your speech to text for free. It is a part of the Open Mind Initiative and runs its operation, especially for developers. Before getting the present name, this program was introduced with different names like VoiceControl, SpeechInput, and FreeSpeech.
Noteworthy Features
- It uses the overflow environment in voice recognition operations to make complex applications flexible.
- Open Mind Speech is mostly compatible with Linux and UNIX-based platforms.
- Using the internet, speech data can be collected from e-citizens, who contribute to raw data.
9. SpeechControl
SpeechControl is a free speech recognition application that is suitable for any Ubuntu distro. It comes with a graphical user interface based on Qt. Though it is still in its early development stage, you can use it for your project.
Noteworthy Features
- Speech Control is an open source program under the General Public License (GPL).
- It aims to work as a virtual assistant that provides repetitive task guidance to execute the process smoothly.
- It is mostly suitable for Linux-based platforms.
- Also, it provides easy-to-understand user documentation with project details.
10. Deepspeech.pytorch
Deepspeech.pytorch is another mentionable open source speech recognition application that is ultimately the implementation of DeepSpeech2 for PyTorch. It contains a set of powerful networks based on DeepSpeech2 architecture. With many helpful resources, it can be used as one of the essential Linux speech recognition tools for research and project development.
Noteworthy Features
- Supports noise augmentation that helps to increase robustness at the time of loading audio.
- It provides a basic server script to send the post request to the server.
- Support several datasets for downloading, including TEDLIUM, AN4, Voxforge, and LibriSpeech.
- It lets you add noise to the training data through noise injection.
- Supports Visdom and Tensorboard for visualizing training on scientific experimentation.
Finishing Thoughts
So, we have reached the finishing point on open source speech recognition tools for Linux. I hope you got comprehensive information regarding this topic. The above-mentioned applications are free, easy to use, and ready to be a part of your academic or personal project.
Which one do you prefer most? If you have any other choices, then don’t hesitate to let us know. Please do share this article with your community if you find it helpful. Till then, have a nice time. Thanks!








I dont understand alot of this github stuff i just need a deb
i just want to talk to my computer
I frequently make live videos (usually streamed by Instagram or Facebook) and I would like to know if there is a software that can automatically transcribe what I say in these videos, like Youtube does automatically for subtitles. Anyone can help? Thanks
I’m searching for a simple speech recognition to create a variable to select audio files to play for a blind person. This lady only wants to listen to a Bible version called The Message Bible. Unfortunately it isn’t available in a manner that doesn’t require the User to respond to visual selections.
I envision a simple command line file triggered by a variable created by her voice when she says something like “Goto the book of Psalms, chapter 23. (since Psalms is indexed by Psalm they would be inside folders marked as chapters.