


Almost all novice data scientists and machine learning developers are being confused about picking a programming language. They always ask which programming language will be best for their machine learning and data science project. Either we will go for python, R, or MatLab. Well, the choice of a programming language depends on developers’ preference and system requirements. Among other programming languages, R is one of the most potential and splendid programming languages that have several R machine learning packages for both ML, AI, and data science projects.
As a consequence, one can develop his project effortlessly and efficiently by using these R machine learning packages. According to a survey of Kaggle, R is one of the most popular open-source machine learning languages.
Best R Machine Learning Packages
R is an open-source language so that people can contribute from anywhere in the world. You can use a Black Box in your code, which is written by someone else. In R, this Black Box is referred to as a package. The package is nothing but a pre-written code that can be used repeatedly by anyone. Below, we are showcasing the top 20 best R machine learning packages.
1. CARET
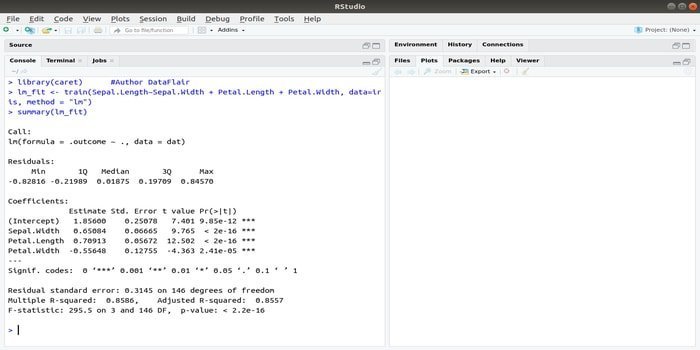

The parameters can be searched by integrating several functions to calculate the overall performance of a given model by using the grid search method of this package. After successful completion of all trials, the grid search finally finds the best combinations.
After installing this package, the developer can run names (getModelInfo()) to see the 217 possible functions that can be run through only one function. For building a predictive model, the CARET package uses a train() function. The syntax of this function:
train(formula, data, method)
2. randomForest
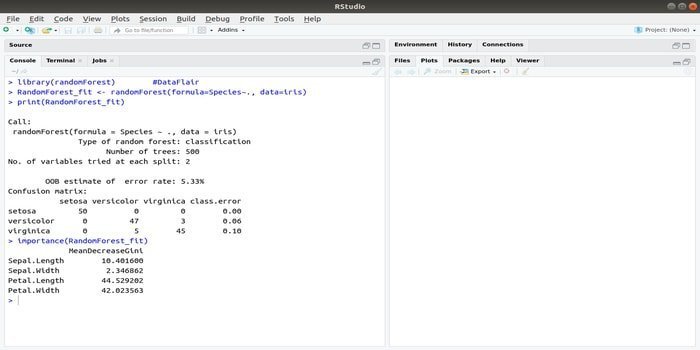
RandomForest is one of the most popular R packages for machine learning. This R machine learning package can be employed for solving regression and classification tasks. Additionally, it can be used for training missing values and outliers.
This machine learning package with R generally is used to generate multiple numbers of decision trees. Basically, it takes random samples. And then, observations are given into the decision tree. Finally, the common output that comes from the decision tree is the ultimate output. The syntax of this function:
randomForest(formula=, data=)
3. e1071
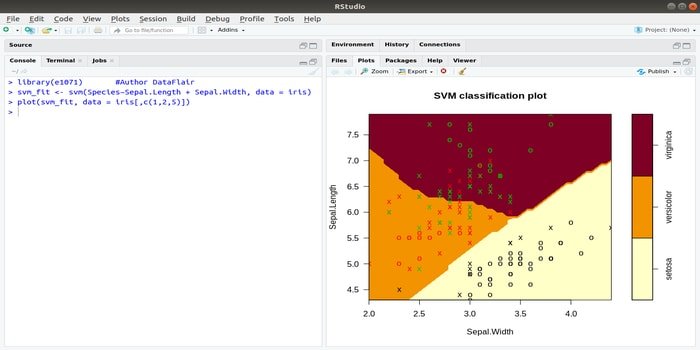
This e1071 is one of the most widely used R packages for machine learning. Using this package, a developer can implement support vector machines (SVM), shortest path computation, bagged clustering, Naive Bayes classifier, short-time Fourier transform, fuzzy clustering, etc.
As an instance, for IRIS data SVM syntax is:
svm(Species ~Sepal.Length + Sepal.Width, data=iris)
4. Rpart
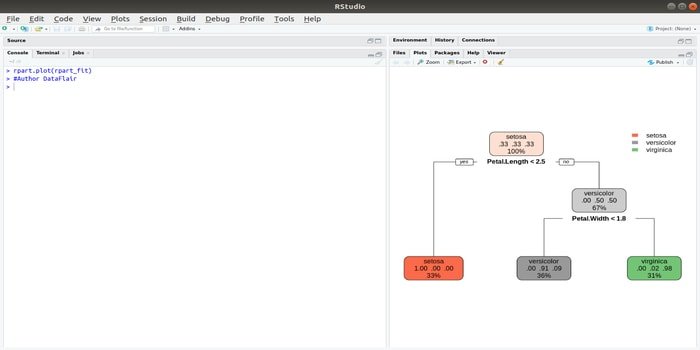
Rpart stands for recursive partitioning and regression training. This R package for machine learning can be performed both tasks: classification and regression. It acts using a two-stage step. The output model a binary tree. The plot() function is used to plot the output result. Also, there is an alternative function, prp() function, that is more flexible and powerful than a basic plot() function.
The function rpart() is used to establish a relationship between independent and dependent variables. The syntax is:
rpart(formula, data=, method=,control=)
where the formula is the combination of independent and dependent variables, data is the name of the dataset, the method is the objective, and control is your system requirement.
5. KernLab
If you want to develop your project based on kernel-based machine learning algorithms, then you can use this R package for machine learning. This package is used for SVM, kernel feature analysis, ranking algorithm, dot product primitives, Gaussian process, and many more. KernLab is widely used for SVM implementations.
There are various kernel functions available. Some kernel functions are mentioned here: polydot (polynomial kernel function), tanhdot (hyperbolic tangent kernel Function), laplacedot (laplacian kernel function), etc. These functions are used for performing pattern recognition problems. But users can use their kernel functions instead of predefined kernel functions.
Documentation
6. nnet
The syntax of this package is:
nnet(formula, data, size)
7. dplyr
One of the most widely used R packages for data science. Also, it provides some easy-to-use, fast, and consistent functions for data manipulation. Hadley Wickham writes this r programming package for data science. This package consists of set of verbs i.e., mutate(), select(), filter(), summarise(), and arrange().
To install this package, one has to write this code:
install.packages(“dplyr”)
And to load this package, you have to write this syntax:
library(dplyr)
8. ggplot2
Another one of the most elegant and aesthetic graphics framework R packages for data science is ggplot2. It’s a system of creating graphics based on the grammar of graphics. The installation syntax for this data science package is:
install.packages(“ggplot2”)
9. Wordcloud

When a single image consists of thousands of words, then it’s called a Wordcloud. Basically, it’s a visualization of text data. This machine learning package using R is used to create a representation of words, and the developer can customize the Wordcloud according to his preference, like arranging the words randomly or same frequency words together or high-frequency words in the center, etc.
In the R machine learning language, two libraries are available to create wordcloud: Wordcloud and Worldcloud2. Here we will show the syntax for WordCloud2. To install WordCloud2, you have to write:
1. require(devtools)
2. install_github(“lchiffon/wordcloud2”)
Or you can use it directly:
library(wordcloud2)
10. tidyr
Another widely used r package for data science is tidyr. The goal of this r programming for data science is tidying the data. In tidy, the variable is placed into the column, observation is placed into the row, and the value is in the cell. This package describes a standard way of sorting data.
For installation, you can use this code fragment:
install.packages(“tidyr”)
For loading, the code is:
library(tidyr)
11. shiny
The R package, Shiny, is one of the web application frameworks for data science. It helps to build up web applications from R effortlessly. Either the developer can install the software on each client system or cab host a webpage. Also, the developer can build dashboards or can embed them in R Markdown documents.
Additionally, Shiny apps can be extended with various scripting languages like html widgets, CSS themes, and JavaScript actions. In a word, we can say that this package is a combination of the computational power of R with the interactivity of the modern web.
12. tm
Needless to say, text mining is an emerging application of machine learning nowadays. This R machine learning package provides a framework for solving text mining tasks. In a text mining application, i.e., sentiment analysis or news classification, a developer has various types of tedious work like removing unwanted and irrelevant words, removing punctuation marks, removing stop words, and many more.
The tm package contains several flexible functions to make your work effortless like removeNumbers(): to remove Numbers from the given text document, weightTfIdf(): for term Frequency and inverse document frequency, tm_reduce(): to combine transformations, removePunctuation() to remove punctuation marks from the given text document and many more.
13. MICE Package

The machine learning package with R, MICE refers to Multivariate Imputation via Chained Sequences. Almost all the time, the project developer faces a common problem with the machine learning dataset that is the missing value. This package can be used to impute the missing values using multiple techniques.
This package contains several functions such as inspecting missing data patterns, diagnosing the quality of imputed values, analyzing completed datasets, storing and exporting imputed data in various formats, and many more.
14. igraph
The network analysis package, igraph, is one of the powerful R packages for data science. It’s a collection of powerful, efficient, easy to use, and portable network analysis tools. Also, this package is open source and free. Additionally, igraphn can be programmed on Python, C/C++, and Mathematica.
This package has several functions to generate random and regular graphs, visualization of a graph, etc. Also, you can work with your large graph using this R package. There are some requirements to use this package: for Linux, a C and a C++ compiler are needed.
The installation of this R programming package for data science is:
install.packages(“igraph”)
For loading this package, you have to write:
library(igraph)
15. ROCR
The R package for data science, ROCR, is used to visualize the performance of scoring classifiers. This package is flexible and easy to use. Only three commands and default values for optional parameters are needed. This package is used to developing cutoff-parameterized 2D performance curves. In this package, there are several functions like prediction(), which are used to create prediction objects, performance() used to create performance objects, etc.
16. DataExplorer
The package DataExplorer is one of the most extensively easy-to-use R packages for data science. Among numerous data science tasks, exploratory data analysis (EDA) is one of them. In exploratory data analysis, the data analyst has to pay more attention in data. It is not an easy job to check out or handle data manually or use poor coding. Automation of data analysis is needed.
This R package for data science provides automation of data exploration. This package is used to scan and analyze each variable and visualize them. It is useful when the dataset is massive. So, the data analysis can extract the hidden knowledge of data efficiently and effortlessly.
The package can be installed from CRAN directly using the below code:
install.packages(“DataExplorer”)
To load this R package, you have to write:
library(DataExplorer)
17. mlr
One of the most incredible packages of R machine learning is the mlr package. This package is encryption of several machine learning tasks. That means you can perform several tasks by only using a single package, and you no need to use three packages for three different tasks.
The package mlr is an interface for numerous classification and regression techniques. The techniques include machine-readable parameter descriptions, clustering, generic re-sampling, filtering, feature extraction, and many more. Also, parallel operations can be done.
For installation, you have to use the below code:
install.packages(“mlr”)
To load this package:
library(mlr)
18. arules
The package, arules (Mining association rules and Frequent Itemsets), is an extensively used R machine learning package. By using this package, several operations can be done. The operations are the representation and transaction analysis of data and patterns and data manipulation. The C implementations of Apriori and Eclat association mining algorithms are also available.
19. mboost
Another R machine learning package for data science is mboost. This model-based boosting package has a functional gradient descent algorithm for optimizing general risk functions by utilizing regression trees or component-wise least squares estimates. Also, it provides an interaction model to potentially high-dimensional data.
20. party
Another package in machine learning with R is party. This computational toolbox is used for recursive partitioning. The main function or core of this machine learning package is ctree(). It is an extensively used function that reduces the time of training and bias.
The syntax of ctree() is:
ctree(formula,data)
Ending Thoughts
R is such a prominent programming language that uses statistical methods and graphs to explore data. Needless to say, this language has several numbers of R machine learning packages, an incredible RStudio tool, and easy-to-understand syntax to develop advanced machine learning projects. In an R ml package, there are some default values. Before applying it to your program, you must have to know about the various options in detail. By using these machine learning packages, anyone can build an efficient machine learning or data science model. Lastly, R is an open-source language, and its packages are continually growing.
If you have any suggestions or queries, please leave a comment in our comment section. You can also share this article with your friends and family via social media.











Outstanding tour of available packages. Thank you.