


We all aware of the beauty of Artificial Intelligence, which reigns the current technology-driven world. This board area relates to the two essential disciplines that are Data Mining and Machine Learning. Both data mining and machine learning originate from the same root that is data science, and also they intersect each other. Moreover, both are data-driven disciplines. Both disciplines help developers to develop an efficient system. However, still, there is a question “Is there a difference between data mining vs. machine learning?” To provide a clear understanding of this question, we outline 20 distinctions between them, which guide you to pick the right discipline to solve your programming problem.
Data mining vs. Machine learning: Interesting Facts


The objective of data mining is to find out the patterns from data. On the other hand, the task of machine learning is to make an intelligent machine that learns from its experience and can take action according to the environment. Generally, machine learning uses data mining approaches and other learning algorithms to develop a model. Below, we are outlining the top 20 key distinctions between data mining vs. machine learning.
1. Meaning of Data Mining and Machine Learning
The term Data Mining means mining data to find out patterns. It extracts knowledge from a large amount of data. The term Machine Learning refers to teaching the machine. That is introducing a new model that can learn from the data as well as its experience.
2. Definition of Data Mining and Machine Learning

The main diffidence between data mining vs. machine learning is how they are defined. Data mining searches information from a large amount of data from different sources. The information can be any type like about medical data, people, business data, specification of a device, or can be anything. The primary purpose of this knowledge discovery technique is to find out patterns from unstructured data and put it together for the future outcome. The mined data can be used for Artificial Intelligence and Machine Learning task.
Machine learning is the study of algorithms that make a machine capable of learning without explicit instructions. It builds a machine such a way that it can act like a human. The main objective of machine learning is to learn from training data and evaluate the model with test data. As an instance, we use Support Vector Machine (SVM) or Naive Bayes to learn the system, and then we predict the outcome based on the trained data.
3. Origin
Now, data mining is everywhere. However, it originates many years before. It originates from the traditional databases. On the other hand, machine learning, which is a subset of artificial intelligence, comes from existing data and algorithms. In machine learning, machines can modify and improve their algorithms by themselves.
4. History
Data mining is a computational process of uncovering patterns from a large volume of data. You may think that as it is the latest technology, so the history of data mining has begun recently. The term data mining was explored in the 1990s. However, it begins in the 1700s with the Bayes Theorem, which is fundamental for data mining. In 1800s Regression analysis is considered as a vital tool in data mining.
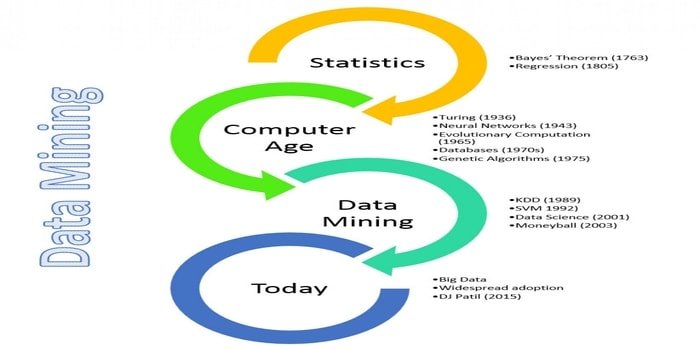
Machine learning is a hot topic for research and industry. This term was introduced in 1950. Arthur Samuel wrote the first program. The program was Samuel’s Checker playing.
5. Responsibility
Data Mining is a set of method that is applied to a large and complicated database. The primary purpose of data mining is to eliminate redundancy and uncover the hidden pattern from the data. Several data mining tools, theories, and methods are used to reveal the pattern in data.
Machine learning teaches the machine or device to learn. In supervised machine learning, the learning algorithm builds a model from a dataset. This dataset has both the inputs and outputs labels. Moreover, in unsupervised machine learning, the learning algorithm builds the model from a set of data which has only the inputs.
6. Applications
One of the key difference between data mining vs. machine learning is how they are applied. Both of these two terms are now applied tremendously in our everyday life. Moreover, their combination is also applied in various domains and solve competitive programming problems.
Data mining is one of the promising fields. Due to the availability of a large amount of data and the necessity to turn this data into information, it has been used in various domains. As an instance, business, medical, finance, telecommunication, and many more.
In finance, to explore the hidden correlation between financial indicators, data mining is used. Also, to predict customer behavior and launch products, it is used. In healthcare, it helps to find out the relationships between diseases and the treatments. In business, retail companies also use data mining.
The digital age is the creation of machine learning. Machine learning has many applications in our life. In sentiment analysis, it is used to extract the emotion from the text. In image processing, it is used to classify the image. ML is also used in healthcare, weather prediction, sales forecasting, document classification, news classification. Moreover, machine learning is used mostly in an information retrieval system. To know about more applications, you may see 20 Best Machine Learning Applications.
7. Nature
The nature of data mining is to put together numerous data from different sources to extract information or knowledge. The data sources can be an internal source, i.e., a traditional database, or an external source, i.e., social media. It does not have its process. Tools are used to reveal information. Also, human effort is needed to integrate data.
Machine learning uses the information which is formed from mined data to make its dataset. Then the required algorithm is applied to this dataset and build a model. It’s an automatic approach. No human effort is needed.
In one word, it can be said that data mining is the food, and machine learning is the organism which consumes the food to perform the function.
8. Data mining vs. Machine learning: Abstraction
Data mining searches information from a massive amount of data. So, the data warehouse is the abstraction of data mining. A data warehouse is the integration of internal and external source. The discipline machine learning makes a machine capable of taking the decision itself. In an abstraction, machine learning reads the machine.
9. Implementation
For the implementation of data mining, the developer can develop its model where he can use data mining techniques. In machine learning, several machine learning algorithms are available such as Decision Tree, Support Vector Machine, Naive Bayes, Clustering, Artificial Neural Network (ANN) and many more to develop the machine learning model.
10. Software

One of the interesting differences between data mining vs. machine learning is what type of software they used to develop the model. For data mining, there is much software on the market. Like, Sisense, it is used by the companies and industries to develop the dataset from various sources. The software Oracle Data Mining is one of the most popular software for data mining. There is more in addition to these, including Microsoft SharePoint, Dundas BI, WEKA, and many more.
Several machine learning software and frameworks are available to develop a machine learning project. Like, Google Cloud ML Engine, it is used to develop high-quality machine learning models. Amazon Machine Learning (AML), it’s a cloud-based machine learning software. Apache Singa is another popular software.
11. Open Source Tools
For data mining, open source tools are Rapid Miner; it is famous for predictive analysis. Another one is KNIME, its an integration platform for data analytics. Rattle, it’s a GUI tool which is used R stats programming language. DataMelt, a multi-platform utility which is used for a large volume of data analysis.
Machine learning open source tools are Shogun, Theano, Keras, Microsoft Cognitive Toolkit (CNTK), Microsoft Distributed Machine learning Toolkit, and many more.
12. Techniques
For data mining technique, it has two components: data pre-processing and data mining. In the pre-processing phase, several tasks have to be done. They are data cleansing, integration of data, data selection, and transformation of data. In the second phase, the evaluation of pattern, and the representation of knowledge are done. On the other hand, for the machine learning technique, machine learning algorithms are applied.
13. Algorithm

In the era of big data, the availability of data has increased. Data mining has many algorithms to handle this massive amount of data. They are the statistically based method, machine learning based method, classification algorithms in data mining, neural network, and many more.
In machine learning, there are also several algorithms are found like supervised machine learning algorithm, unsupervised machine learning algorithm, semi-supervised learning algorithm, clustering algorithm, regression, Bayesian algorithm, and many more.
14. Data mining vs. Machine learning: Scope
The scope of data mining is limited. Because the self-learning capability is absent in the field of data mining, data mining can only follow predefined rules. Also, it can provide a particular solution for a particular problem.
Machine learning, on the other hand, can be applied in a vast area as machine learning techniques are self-defined and can change as per the environment. It can find out the solution for the problem with its capability.
15. Data mining vs. Machine learning: Projects
Data mining is used to extract knowledge from a broad set of data. So, data mining projects are those where numerous data is available. In medical science, data mining is used to detect fraud abuses in medical science and to identify successful therapy for illness. In banking, it is used to analyze customer behavior. In research, data mining is used for pattern recognition. Besides these, several fields use a data mining technique to develop their projects.
There are many exciting projects in machine learning, such as identifying product bundles, sentiment analysis of social media, music recommendation system, sales prediction, and many more.
16. Pattern Recognition

Pattern recognition is another factor by which we can differentiate these two terms profoundly. Data mining can uncover hidden patterns by using classification and sequence analysis. Machine learning, on the other hand, uses the same concept but in a different way. Machine learning uses the same algorithms that data mining uses, but it uses the algorithm to learn automatically from data.
17. Foundations for Learning
A data scientist applies data mining techniques to extract hidden patterns that can help for the future outcome. As an instance, a clothing company uses data mining technique to their large amount of customer records to form their look for the next season. Also, to explore best selling products, customer feedback for the products. This use of data mining can enhance the customer experience.
Machine learning, on the other hand, learns from the training data, and this is the foundation for developing the machine learning model.
18. Future of Data Mining and Machine Learning
The future of data mining is so much promising as the amount of data has increased tremendously. With the rapid growth of blogs, social media, micro-blogs, online portals, the data is so much available. The future data mining points to predictive analysis.
Machine learning, on the other hand, is also demanding. As humans are now addicted to machines, so the automation of device or machine is getting favorite day by day.
19. Data mining vs. Machine learning: Accuracy
Accuracy is the main concern of any system. In terms of accuracy, machine learning outperforms than the data mining technique. The result generated by machine learning is more accurate as machine learning is an automated process. On the other hand, data mining can not work without the involvement of human.
20. Purpose
The purpose of data mining is to extract hidden information, and this information helps to predict further results. As an instance, in a business company, it uses previous year data to predict next year sale. However, in a machine learning technique, it does not depend on the data. Its purpose is to use a learning algorithm to perform its given task. For example, to develop a news classifier, Naive Bayes is used as a learning algorithm.
Ending Thoughts
Machine learning is growing much faster than data mining as data mining can only act upon the existing data for a new solution. Data mining is not capable of taking its own decision, whereas machine learning is capable. Also, machine learning gives a more accurate result than data mining. However, we need data mining to define the problem by extracting hidden patterns from the data and resolve such problem we need machine learning. So, in one word, we can say we need both machine learning and data mining to develop a system. Because data mining defines the problem and machine learning solves the problem more accurately.
If you have any suggestion or query, please leave a comment in our comment section. You can also share this article with your friends and family via social media.










