


Storing and processing big data has remained the biggest challenge until today since the beginning of its journey. It is important to be able to compute datasets to generate solutions for businesses. But sometimes, it becomes really challenging to produce accurate results due to the outliers, scarcity of sources, Volume, and inconsistency. But there is no value of big data if you can not use it or extract meaningful information. The below mentioned Hadoop Interview Questions would help you to get a solid foundation and face interviews as well.
Hadoop is a great solution or can be seen as a data warehouse that can store and process big data efficiently. It helps to bring out insights and knowledge easily. Besides, data modeling, data analytics, data scalability, and data computations capabilities have made Hadoop so popular among companies and individuals. So it is important to go through these Hadoop Interview Questions if you want to establish your career around cloud computing.
Hadoop is developed by Apache Software Foundation. It started the journey on April 1, 2006, and licensed under Apache License 2.0. It is a framework that allows people to work with massive amounts of data. Besides, it uses the MapReduce algorithm and ensures high availability, which is the most exclusive feature any business can offer. You should make sure that you understand all the basic concepts of cloud computing. Otherwise, you will face trouble while going through the following Hadoop interview questions.
Hadoop Interview Questions and Answers
It is important to go through these Hadoop Interview Questions in-depth if you are a candidate and want to start a job in the cloud computing industry. These questions and answers covered throughout this article will definitely help you to be on the right track.
As most companies are running businesses based on the decisions derived from analyzing big data, more skillful people are required to produce better results. It can improve an individual’s efficiency and thus contribute to generating sustainable results. As a collection of open-source software utilities, it can process huge datasets across clusters of computers. This article highlights all the basics and advanced topics of Hadoop. Besides, it will save a lot of time for you and prepare yourself well enough for the interviews.
Q-1. What is Hadoop?

As a collection of open-source software utilities, it turned out to be a great system that helps in making data-driven decisions and manage businesses effectively and efficiently. It was developed by Apache Software Foundation and licensed under Apache License 2.0.
Cluster Rebalancing: Automatically free up the space of data nodes approaching a certain threshold and rebalances data.
Accessibility: There are so many ways to access Hadoop from different applications. Besides, the web interface of Hadoop also allows you to browse HDFS files using any HTTP browser.
Re-replication: In case of a missing block, NameNode recognizes it as a dead block, which is then re-replicated from another node. It protects the hard disk from failure and decreases the possibility of data loss.
Q-2. Mention the names of the foremost components of Hadoop.
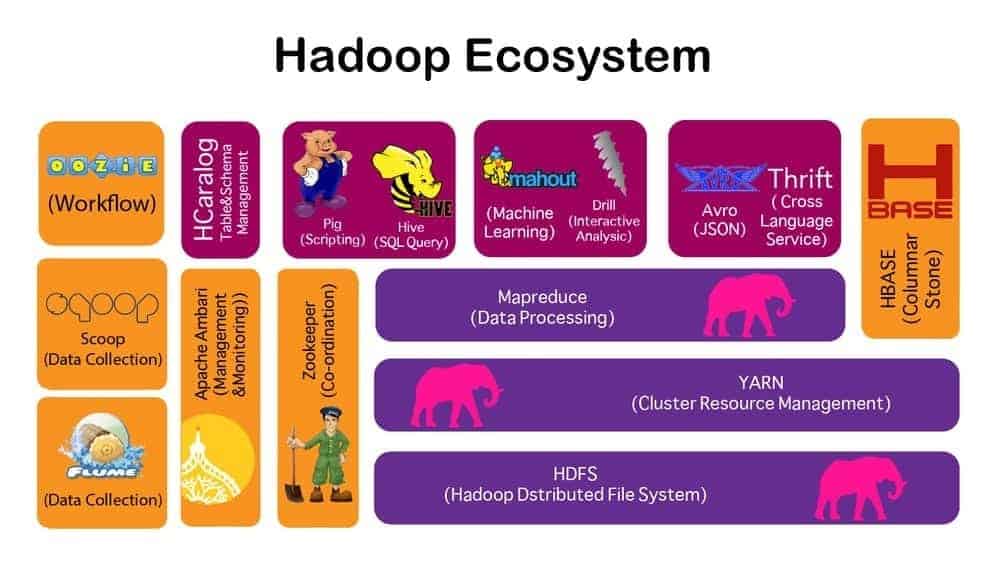

HDFS: Used for storing data and all the applications.
MapReduce: Used for processing of stored data and driving solutions through computation.
YARN: Manages the resources that are present in Hadoop.
Interviewers love to ask these Hadoop admin interview questions because of the amount of information they can cover and judge the candidate’s capability very well.
Q-3. What do you understand by HDFS?
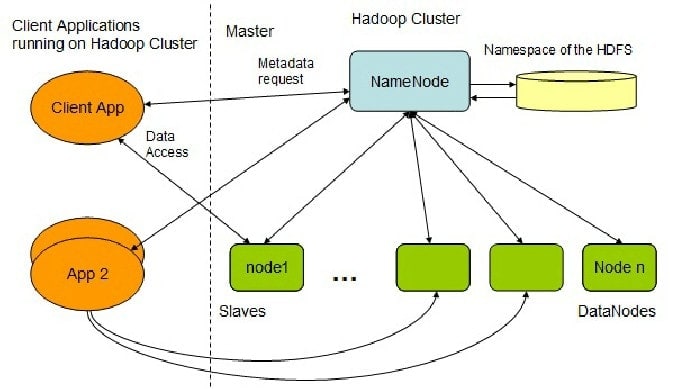

NameNode: It can be referred to as the master node, which contains the metadata information such as block location, factors of replication, and so on for each data block stored in Hadoop’s distributed environment.
DataNode: It is maintained by NameNode and works as a slave node to store data in HDFS.
This is one of the most important frequently asked Hadoop Interview Questions. You can easily expect this question on your coming interviews.
Q-4. What is YARN?
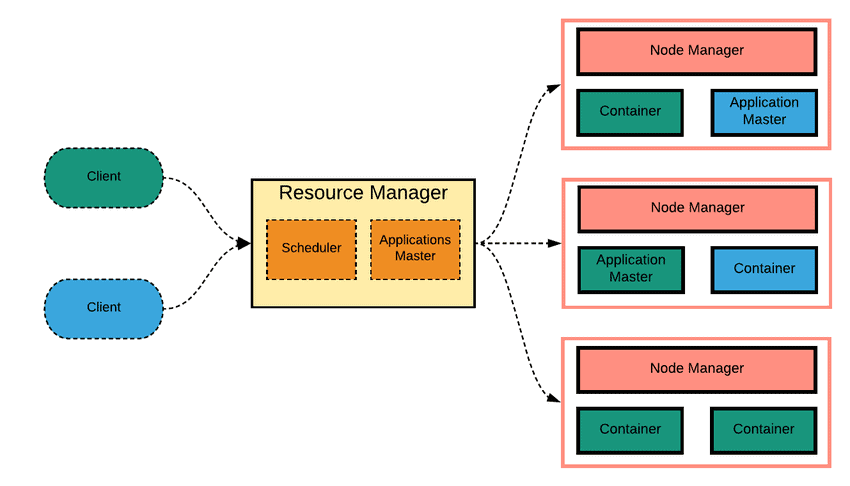

ResourceManager: It delivers the resources to the application according to the requirement. Besides, it is responsible for receiving the processing requests and forwarding them to the associated NodeManager.
NodeManager: After receiving the resources from ResourceManager, NodeManager starts processing. It is installed on every data node and performs the execution task as well.
Q-5. Can you mention the principal differences between the relational database and HDFS?


Data types: Relational databases depend on the structures data while the schema can also be known. On the other hand, structured, unstructured, or semi-structured data is allowed to store in HDFS.
Processing: RDBMS does not have the processing ability, while HDFS can process datasets to execute in the distributed clustered network.
Schema: Schema validation is done even before the data is loaded when it comes to RDBMS, as it follows schema on write fashion. But HDFS follows a schema on reading policy for validating data.
Read/Write Speed: As data is already known, reading is fast in the relational database. On the contrary, HDFS can write fast due to the absence of data validation during the writing operation.
Cost: You will need to pay for using a relational database as it is a licensed product. But Hadoop is an open-source framework so it will not cost even a penny.
Best-fit Use Case: RDBMS is suitable to use for Online Transactional Processing while Hadoop can be used for many purposes, and it can also enhance the functionalities of an OLAP system like data discovery or data analytics.
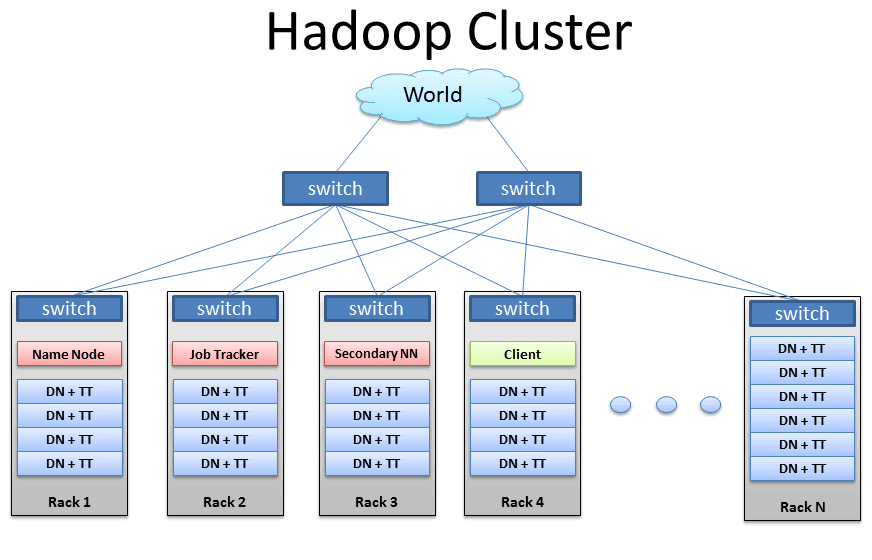
Q-6. Explain the role of various Hadoop daemons in a Hadoop cluster.
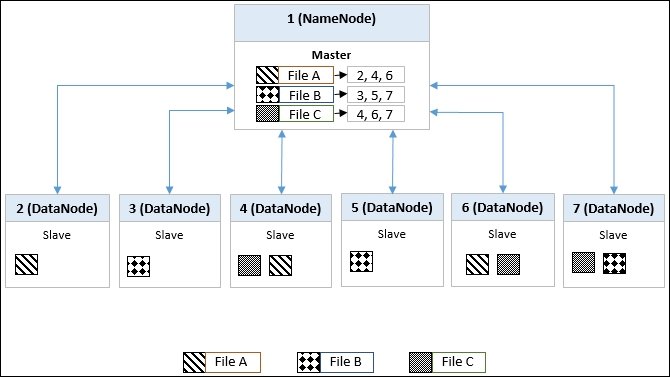

Q-7. How can we discriminate HDFS and NAS?
The differences between HDFS and NAS asked in this Hadoop related question can be explained as follows:
- NAS is a file-level server that is used to provide access to a heterogeneous group through a computer network. But when it comes to HDFS, it utilizes commodity hardware for storing purpose.
- If you store data in HDFS, it becomes available to all the machines connected to the distributed cluster while in Network Attached Storage, data remains visible only to the dedicated computers.
- NAS can not process MapReduce due to the absence of communication between data blocks and computation, while HDFS is known for its capability of working with the MapReduce paradigm.
- Commodity hardware is used in HDFS to decrease the cost while NAS uses high-end devices, and they are expensive.
Q-8. How does Hadoop 2 function better than Hadoop 1?
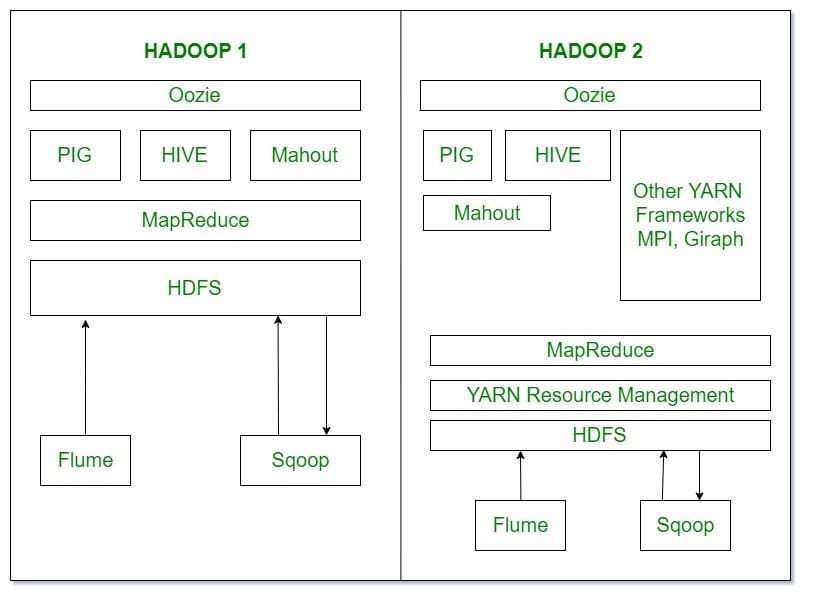

There is a central manager in YARN, which allows us to run multiple applications in Hadoop. Hadoop 2 utilizes the power of the MRV2 application, which can operate the MapReduce framework on top of YARN. But other tools can not use YARN for data processing when it comes to Hadoop 1.
Q-9. What can be referred to as active and passive “NameNodes”?
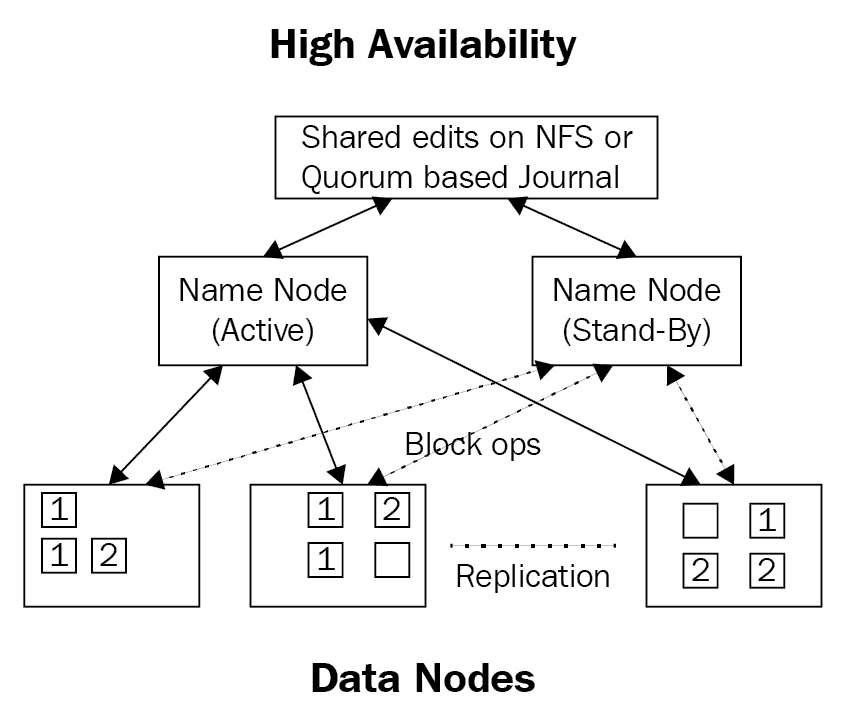

But in these circumstances, passive NameNode plays an important role that contains the same resources as active NameNode. It can replace the active NameNode when required so the system can never fail.
Q-10. Why adding or removing nodes is done frequently in the Hadoop cluster?
Hadoop framework is scalable and popular for its capability of utilizing the commodity hardware. DataNode crashing is a common phenomenon in the Hadoop cluster. And again, the system automatically scales according to the Volume of data. So, it can be easily understood that commissioning and decommissioning DataNodes is done rapidly, and it is one of the most striking features of Hadoop.
Q-11. What happens when HDFS receives two different requests for the same resource?
Although HDFS can handle several clients at a time, it supports exclusive writes only. That means if a client asks to get access to an existing resource, HDFS responds by granting permission. As a result, the client can open the file for writing. But when another client asks for the same file, HDFS notices the file is already leased to another client. So, it automatically rejects the request and let the client know.
Q-12. What does NameNode do when DataNode fails?
If the DataNode is working properly, it can transmit a signal from each DataNode in the cluster to the NameNode periodically and known as the heartbeat. When no heartbeat message is transmitted from the DataNode, the system takes some time before marking it as dead. NameNode gets this message from the block report where all the blocks of a DataNode are stored.
If NameNode identifies any dead DataNode, it performs an important responsibility to recover from the failure. Using the replicas that have been created earlier, NameNode replicates the dead node to another DataNode.
Q-13. What are the procedures needed to be taken when a NameNode fails?
When NameNode is down, one should perform the following tasks to turn the Hadoop cluster up and run again:
- A new NameNode should be created. In this case, you can use the file system replica and start a new node.
- After creating a new node, we will need to let clients and DataNodes know about this new NameNode so that they can acknowledge it.
- Once you complete the last loading checkpoint known as FsImage, the new NameNode is ready to serve the clients. But to get going, NameNode must receive enough block reports coming from the DataNodes.
- Do routine maintenance as if NameNode is down in a complex Hadoop cluster, it may take a lot of effort and time to recover.
Q-14. What is the role of Checkpointing in the Hadoop environment?

As a result, the system becomes more efficient, and the required startup time of NameNode can also be reduced. To conclude, it should be noted that this process is completed by the Secondary NameNode.
Q-15. Mention the feature, which makes the HDFS fraud tolerant.
This Hadoop related question asks whether HDFS is fraud tolerant or not. The answer is yes, HDFS is fraud tolerant. When data is stored, NameNode can replicate data after storing it to several DataNodes. It creates 3 instances of the file automatically as the default value. However, you can always change the number of replication according to your requirements.
When a DataNode is labeled as dead, NameNode takes information from the replicas and transfers it to a new DataNode. So, the data becomes available again in no time, and this process of replication provides fault tolerance in the Hadoop Distributed File System.
Q-16. Can NameNode and DataNodefunction like commodity hardware?
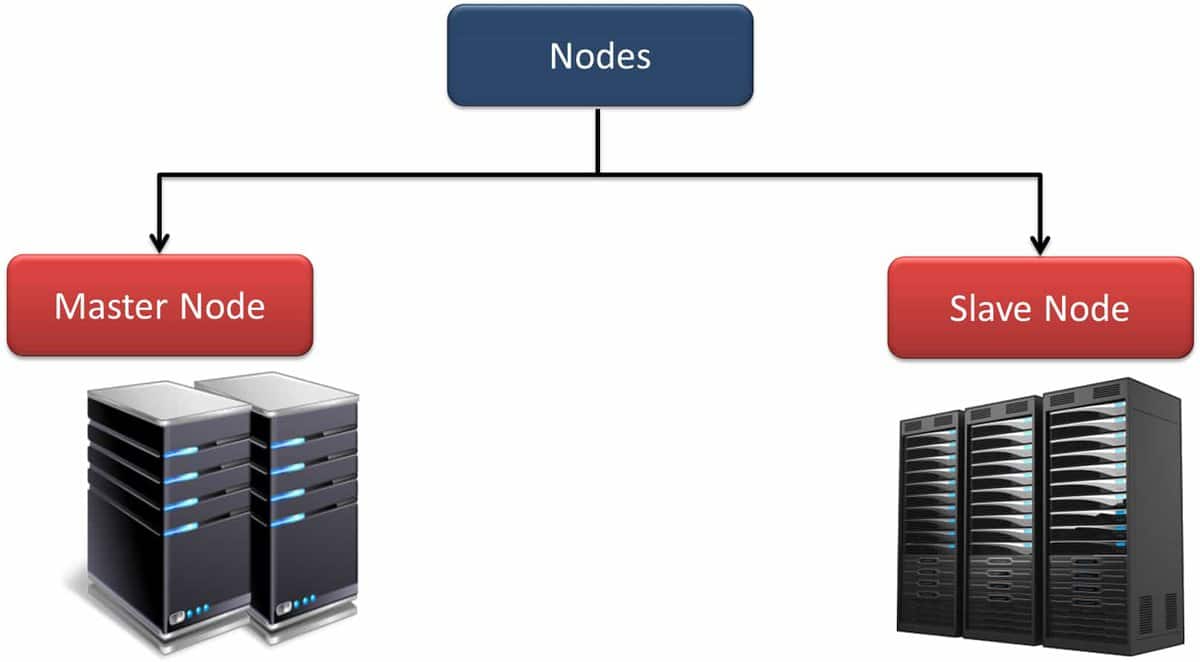

Again, NameNode contains metadata about all data blocks in HDFS, and it takes a lot of computational power. It can be compared to random access memory or RAM as a High-End Device, and good memory speed is required to perform these activities.
Q-17. Where should we use HDFS? Justify your answer.
When we need to deal with a large dataset that is incorporated or compacted into a single file, we should use HDFS. It is more suitable to work with a single file and is not much effective when the data is spread in small quantities across multiple files.
NameNode works like a RAM in the Hadoop distribution system and contains metadata. If we use HDFS to deal with too many files, then we will be storing too many metadata. So NameNode or RAM will have to face a great challenge to store metadata as each metadata may take minimum storage of 150 bytes.
Q-18. What should we do to explain “block” in HDFS?
Do you know the default block size of Hadoop 1 and Hadoop 2?
Blocks can be referred to as continuous memory on the hard drive. It is used to store data, and as we know, HDFS stores each data as a block before distributing it throughout the cluster. In the Hadoop framework, files are broken down into blocks and then stored as independent units.
- Default block size in Hadoop 1: 64 MB
- Default block size in Hadoop 2: 128 MB
Besides, you can also configure the block size using the dfs.block.size parameter. If you want to know the size of a block in HDFS, use the hdfs-site.xml file.
Q-19. When do we need to use the ‘jps’ command?
Namenode, Datanode, resourcemanager, nodemanager, and so on are the available daemons in the Hadoop environment. If you want to have a look at all the currently running daemons on your machine, use ‘jps’ command to see the list. It is one of the frequently used commands in HDFS.
Interviewers love to ask command related Hadoop developer interview questions, so try to understand the usage of frequently used commands in Hadoop.
Q-20. What can be referred to as the five V’s of Big Data?
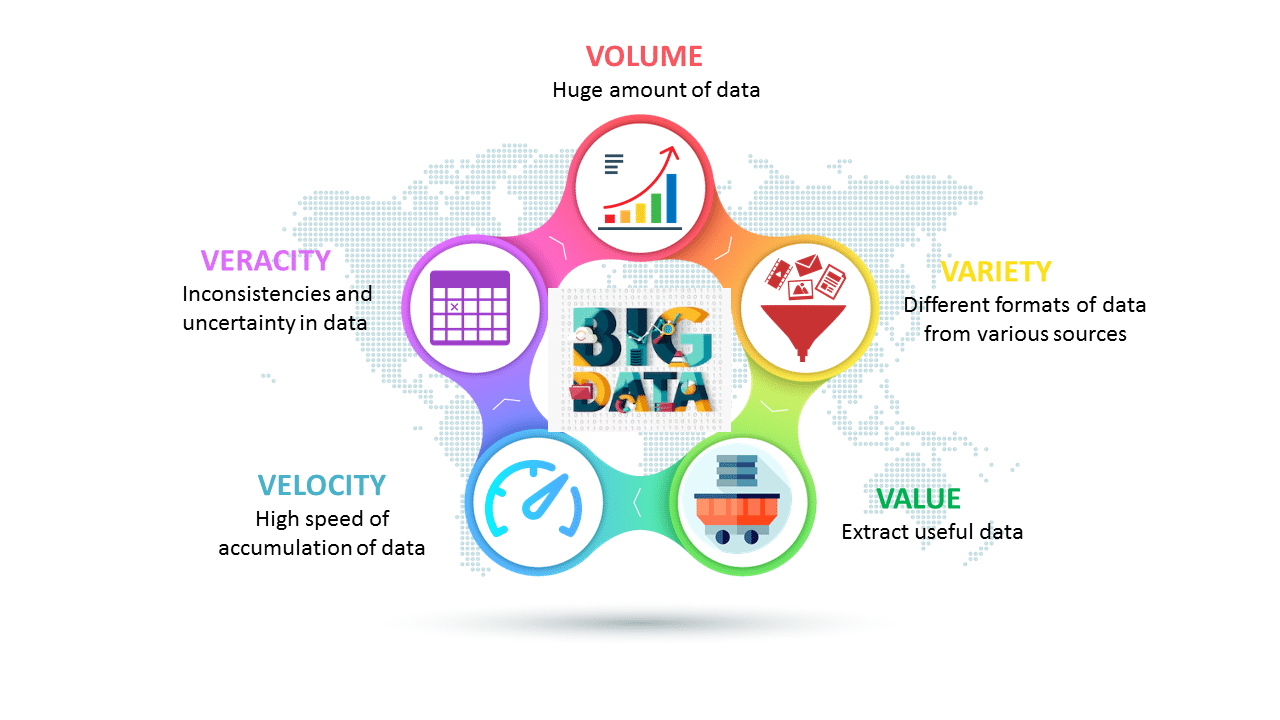

Velocity: Big data deals with the ever-growing dataset that can be huge and complicated to compute. Velocity refers to the increasing data rate.
Volume: Represents the Volume of data that grows at an exponential rate. Usually, Volume is measured in Petabytes and Exabytes.
Variety: It refers to the wide range of variety in data types such as videos, audios, CSV, images, text, and so on.
Veracity: Data often becomes incomplete and becomes challenging to produce data-driven results. Inaccuracy and inconsistency are common phenomenons and known as veracity.
Value: Big data can add value to any organization by providing advantages in making data-driven decisions. Big data is not an asset unless the value is extracted out of it.
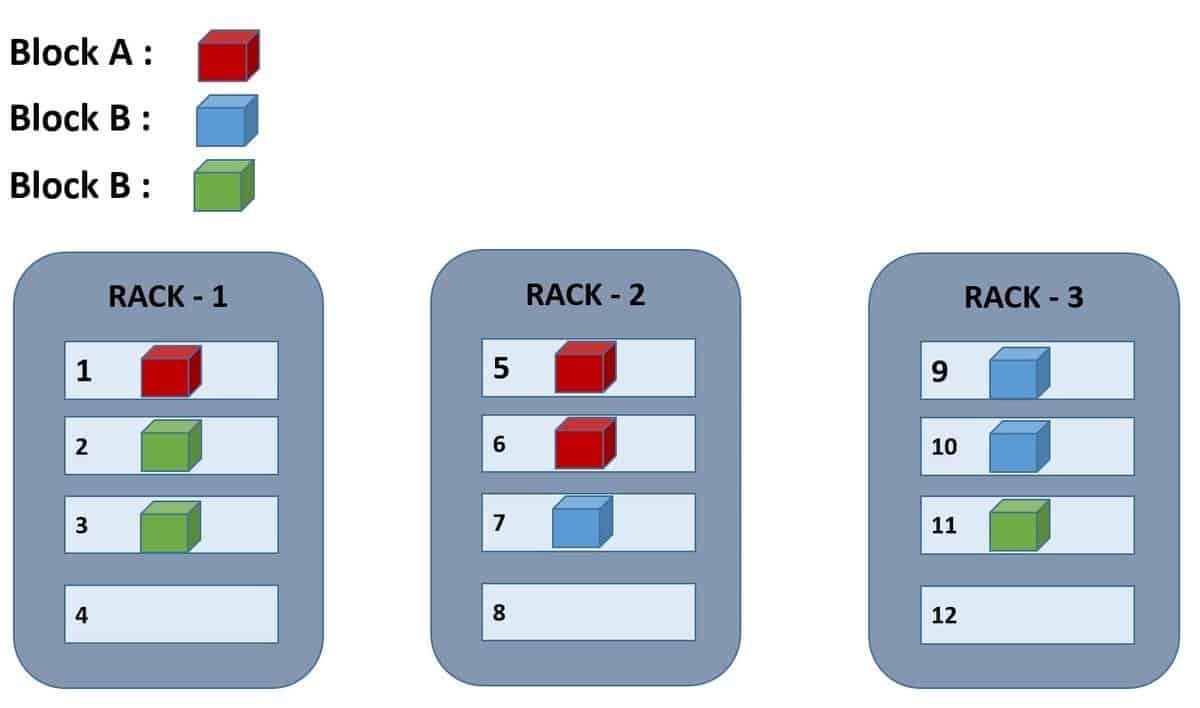
Q-21. What do you mean by “Rack Awareness” in Hadoop?

Q-22. Describe the role of “Speculative Execution” in Hadoop?
![]()

Q-23. What should we do to perform the restart operation for “NameNode” in the Hadoop cluster?
Two distinct methods can enable you to restart the NameNode or the daemons associated with the Hadoop framework. To choose the most suitable process to restart “NameNode” have a look at your requirements.
If you want to stop the NameNode only /sbin /hadoop-daemon.sh stop namenode command can be used. To start the NameNode again use /sbin/hadoop-daemon.sh start namenode command.
Again, /sbin/stop-all.sh command is useful when it comes to stopping all the daemons in the cluster while ./sbin/start-all.sh command can be used for starting all the daemons in the Hadoop framework.
Q-24. Differentiate “HDFS Block” and an “Input Split”.
It is one of the most frequently asked Hadoop Interview Questions. There is a significant difference between HDFS Block and Input Split. HDFS Block divides data into blocks using MapReduce processing before assigning it to a particular mapper function.
In other words, HDFS Block can be viewed as the physical division of data, while Input Split is responsible for the logical division in the Hadoop environment.
Q-25. Describe the three modes that Hadoop can run.
The three modes which Hadoop framework can run are described below:
Standalone mode: In this mode, NameNode, DataNode, ResourceManager, and NodeManager function as a single Java process that utilizes a local filesystem, and no configuration is required.
Pseudo-distributed mode: Master and slave services are executed on a single compute node in this mode. This phenomenon is also known as the running mode in HDFS.
Fully distributed mode: Unlike the Pseudo-distributed mode, master and slave services are executed on fully distributed nodes that are separate from each other.
Q-26. What is MapReduce? Can you mention its syntax?
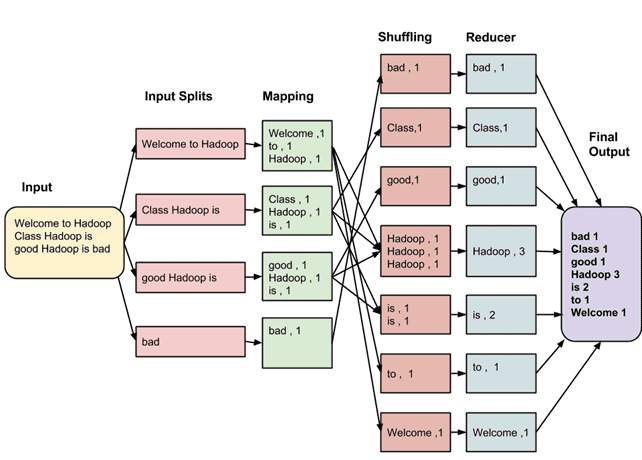

As a programming model or process MapReduce can handle big data over a cluster of computers. It uses parallel programming for computing. If you want to run a MapReduce program, you can use “hadoop_jar_file.jar /input_path /output_path” like syntax.
Q-27. What are the components that are required to be configured for a MapReduce program?
This Hadoop related question asks about the parameters to run a MapReduce program components needed to be configured mentioned below:
- Mention the input locations of jobs in HDFS.
- Define the locations where the output will be saved in HDFS.
- Mention the input type of data.
- Declare the output type of data.
- The class that contains the required map function.
- The class that contains the reduce function.
- Look for a JAR file to get the mapper reducer, and driver classes.
Q-28. Is it possible to perform the “aggregation” operation in the mapper?
It is a tricky Hadoop related question in the list of Hadoop Interview Questions. There can be several reasons which are stated as follows:
- We are not allowed to perform sorting in the mapper function as it is meant to be performed only on the reducer side. So we can not perform aggregation in mapper as it is not possible without sorting.
- Another reason can be, If mappers run on different machines, then it is not possible to perform aggregation. Mapper functions may not be free, but it is important to collect them in the map phase.
- Building communication between the mapper functions is crucial. But as they are running on different machines, it will take High bandwidth.
- Network bottlenecks can be considered as another common result if we want to perform aggregation.
Q-29. How does “RecordReader” perform in Hadoop?
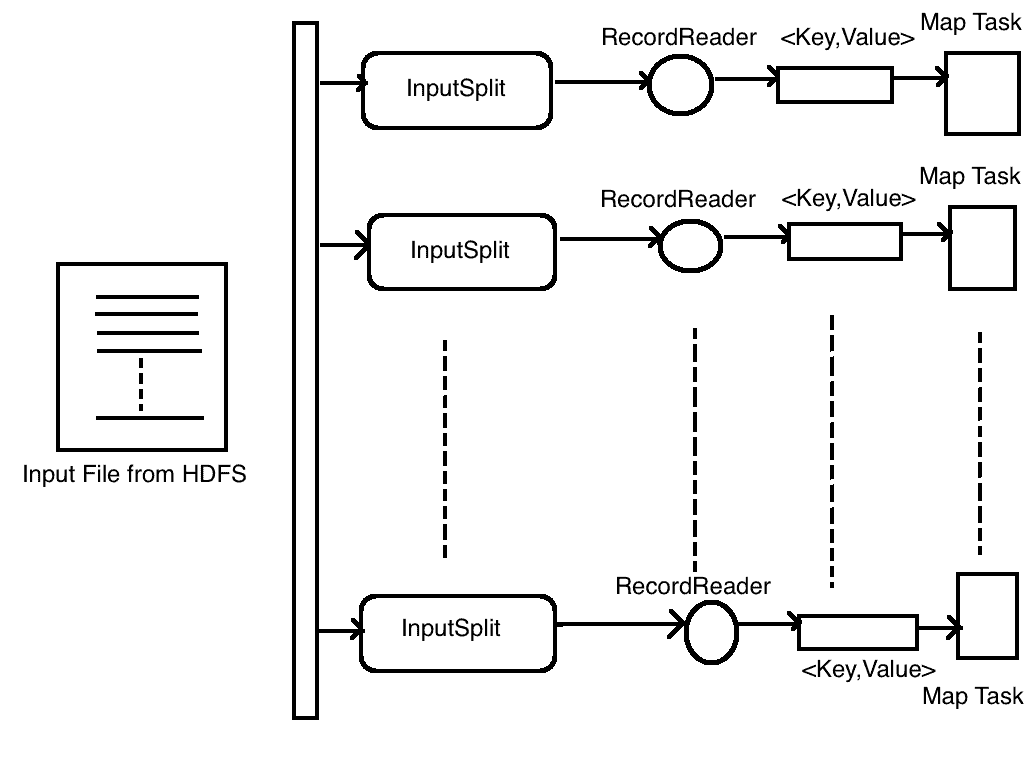

Q-30. Why does “Distributed Cache” play an important role in a “MapReduce Framework”?
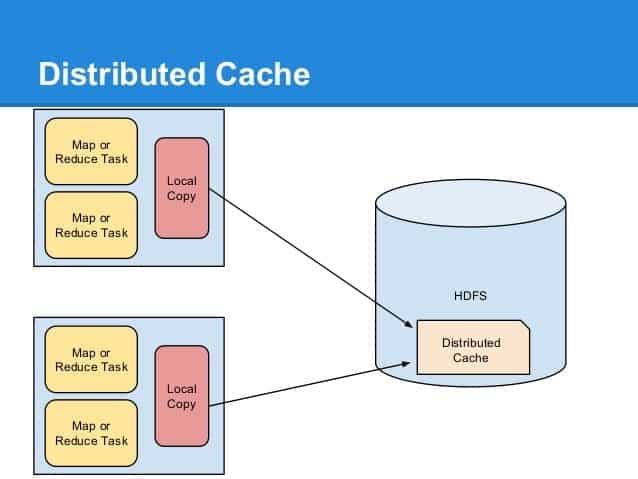

Q-31. What is the communication process between reducers?
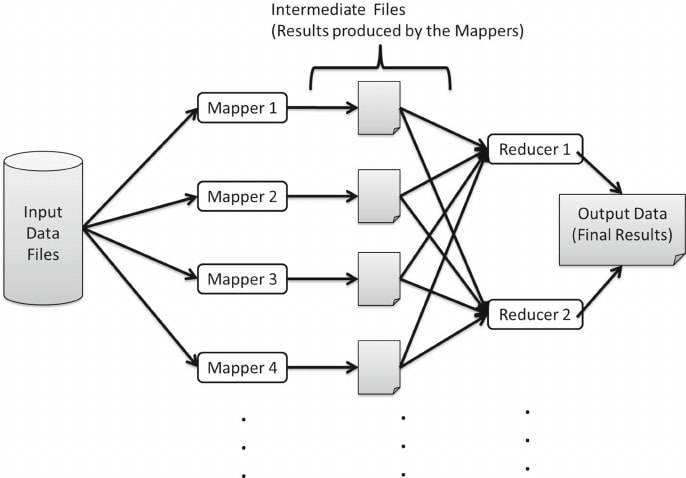

Q-32. How does the “MapReduce Partitioner” play a role in Hadoop?
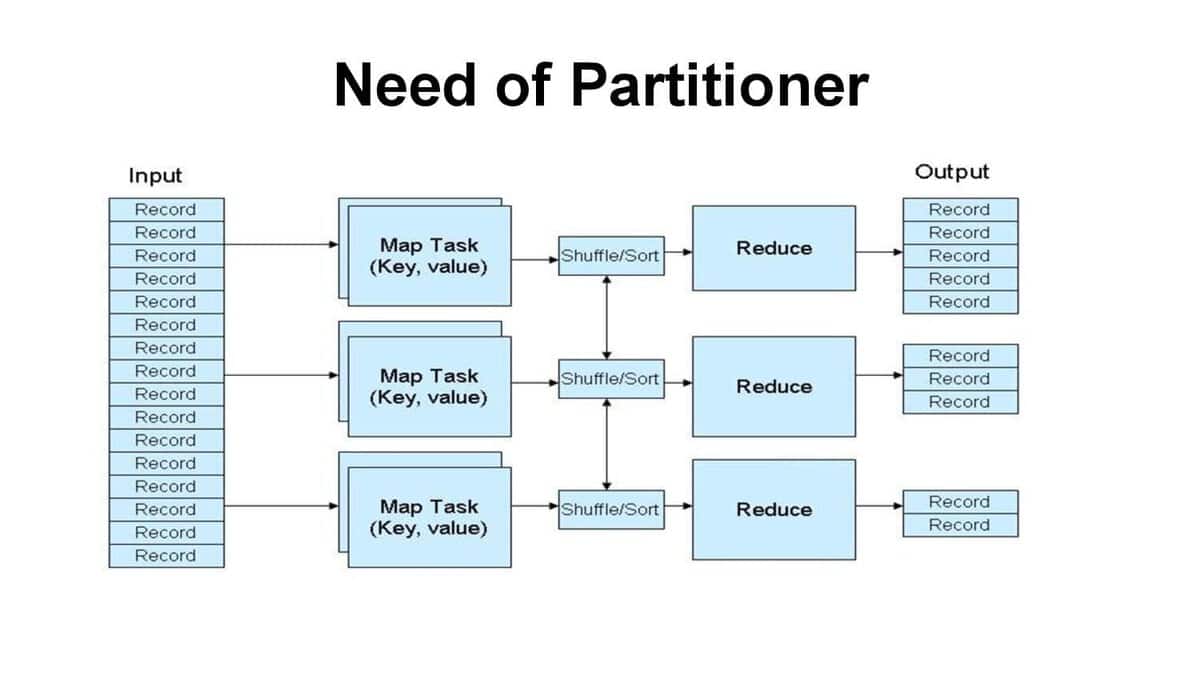

Q-33. Mention the process of writing a custom partitioner?
If you want to write a custom partitioner, then you should follow the following steps:
- At first, you will need to create a new class that can extend the Partitioner Class.
- Secondly, use the getPartition override method in the wrapper so that it can run MapReduce.
- Set Partitioner for adding the custom Partitioner to a job should be used at this point. However, you can also add a custom partitioner as a config file.
Q-34. What do you mean by a “Combiner”?
A “Combiner” can be compared to a mini reducer that can perform the “reduce” task locally. It receives the input from the “mapper” on a particular “node” and transmits it to the “reducer”. It reduces the volume of data required to send to the “reducer” and improves the efficiency of MapReduce. This Hadoop related question is really important for any cloud computing interview.
Q-35. What is “SequenceFileInputFormat”?
It is an input format and suitable for performing the reading operation within sequence files. This binary file format can compress and optimizes the data so that it can be transferred from the outputs of one “MapReduce” job to the input of another “MapReduce” job.
It also helps in generating sequential files as the output of MapReduce tasks. The intermediate representation is another advantage that makes data suitable for sending from one task to another.
Q-36. What do you mean by shuffling in MapReduce?
The MapReduce output is transferred to as the input of another reducer at the time of performing the sorting operation. This process is known as “Shuffling”. Focus on this question as the interviewers love to ask Hadoop related questions based on operations.
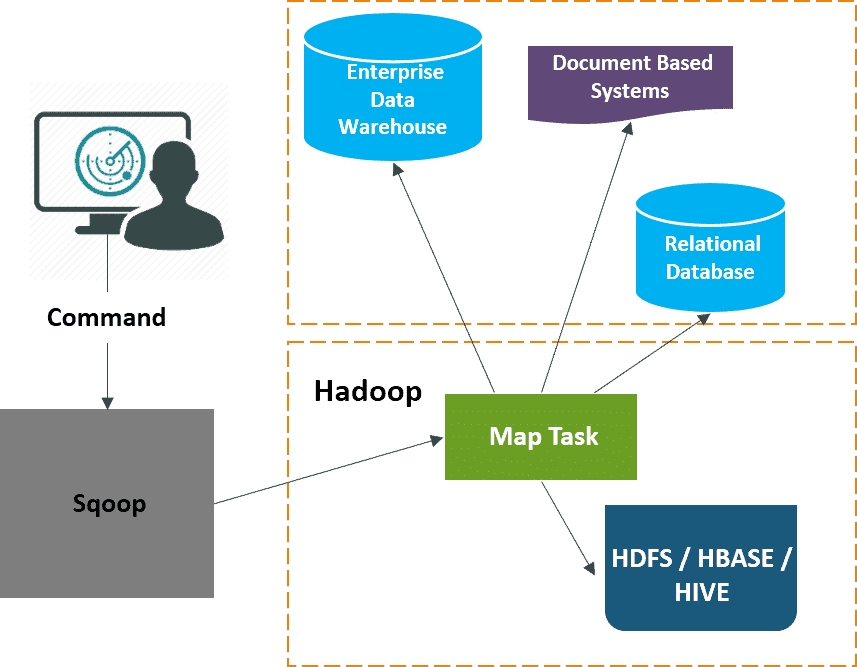
Q-37. Explain Sqoop in Hadoop.

Q-38. What is the role of conf.setMapper class?
This Hadoop related question asks about Conf.setMapper class that has several important roles to play in Hadoop clusters. It sets the mapper class while it also contributes to mapping to jobs. Setting up reading data and generating a key-value pair out of the mapper is also part of its responsibilities.
Q-39. Mention the names of data and storage components. How to declare the input formats in Hadoop?
This Hadoop related question can be asked by the interviewers as this covers a lot of information about data type, storage type, and input format. There are two data components used by Hadoop, and they are Pig and Hive, while Hadoop uses HBase components to store data resources.
You can use any of these formats to define your input in Hadoop, which are TextInputFormat, KeyValueInputFormat, and SequenceFileInputFormat.
Q-40. Can you search for files using wildcards? Mention the list of configuration files used in Hadoop?
HDFS allows us to search for files using wildcards. You can import the data configuration wizard in the file/folder field and specify the path to the file to conduct a search operation in Hadoop. The three configuration files Hadoop uses are as follows:
- core-site.xml
- mapred-site.xml
- Hdfs-site.xml
Q-41. Mention the network requirements for using HDFS.

- Password-less SSH connection
- Secure Shell (SSH) for launching server processes
Many people fail to answer this kind of basic Hadoop Interview Questions correctly as we often ignore the basic concepts before diving into the insights.
Q-42. How can we copy files in HDFS? How can you differentiate Hadoop from other data processing tools?
It is an interesting question in the list of most frequently asked Hadoop developer interview questions. HDFS deals with big data and intended to process for adding value. We can easily copy files from one place to another in the Hadoop framework. We use multiple nodes and the distcp command to share the workload while copying files in HDFS.
There are many data processing tools available out there, but they are not capable of handling big data and processing it for computing. But Hadoop is designed to manage big data efficiently, and users can increase or decrease the number of mappers according to the Volume of data needed to be processed.
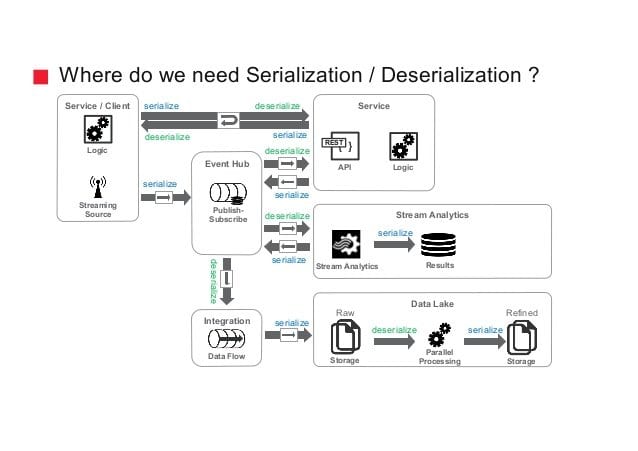
Q-43. How does Avro Serialization operate in Hadoop?

Q-44. What are the Hadoop schedulers? How to keep an HDFS cluster balanced?
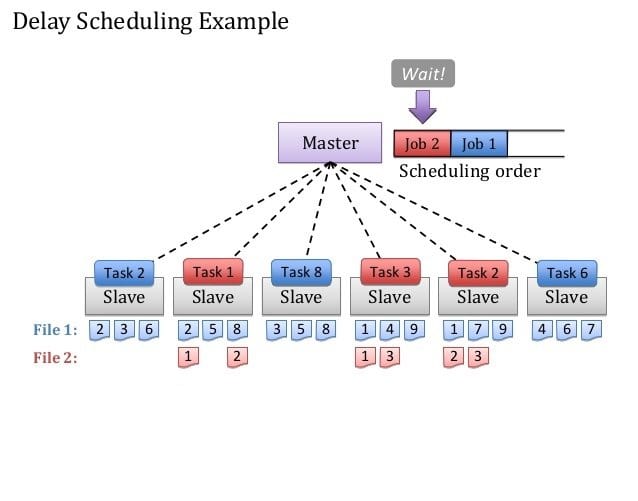

- Hadoop FIFO scheduler
- Hadoop Fair Scheduler
- Hadoop Capacity Scheduler
You can not really limit a cluster from being unbalanced. But a certain threshold can be used among data nodes to provide a balance. Thanks to the balancer tool. It is capable of even out the block data distribution subsequently across the cluster to maintain the balance of the Hadoop clusters.
Q-45. What do you understand by block scanner? How to print the topology?
Block Scanner ensures the high availability of HDFS to all the clients. It periodically checks DataNode blocks to identify bad or dead blocks. Then it attempts to fix the block as soon as possible before any clients can see it.
You may not remember all the commands during your interview. And that’s why command related Hadoop admin interview questions are really important. If you want to see the topology, you should use hdfs dfsadmin -point the topology command. The tree of racks and DataNodes that are attached to the tracks will be printed.
Q-46. Mention the site-specific configuration files available in Hadoop?
The site-specific configuration files that are available to use in Hadoop are as follows:
- conf/Hadoop-env.sh
- conf/yarn-site.xml
- conf/yarn-env.sh
- conf/mapred-site.xml
- conf/hdfs-site.xml
- conf/core-site.xml
These basic commands are really useful. They will not only help you to answer Hadoop Interview Questions but also get you going if you are a beginner in Hadoop.
Q-47. Describe the role of a client while interacting with the NameNode?
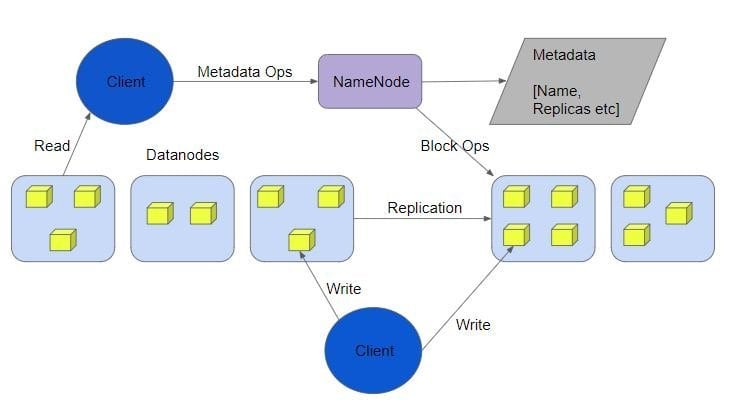

- Clients can associate their applications with the HDFS API to the NameNode so that it can copy/move/add/locate/delete any file when required.
- DataNode servers that contain data will be rendered in a list by the NameNode when it receives successful requests.
- After the NameNode replies, the client can directly interact with the DataNode as the location is now available.
Q-48. What can be referred to as Apache Pig?
Apache Pig is useful to create Hadoop compatible programs. It is a high-level scripting language or can be seen as a platform made with Pig Latin programming language. Besides, the Pig’s capability to execute the Hadoop jobs in Apache Spark or MapReduce should also be mentioned.
Q-49. What are the data types you can use in Apache Pig? Mention the reasons why Pig is better than MapReduce?
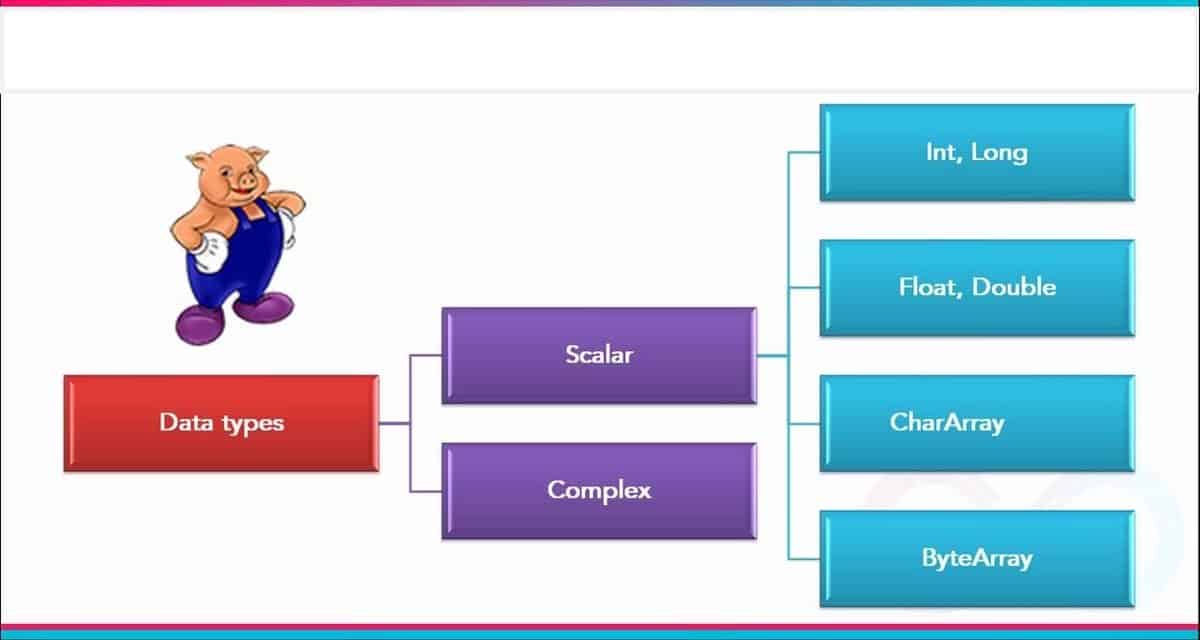

You can achieve many benefits if you choose Pig over Hadoop such as:
- MapReduce is a low-level scripting language. On the other hand, Apache Pig is nothing but a high-level scripting language.
- It can easily complete the operations or implementations which take complex java implementations using MapReduce in Hadoop.
- Pig produces compacted code, or the length of the code is less than Apache Hadoop, which can save development time to a great extent.
Data operations are made easy in Pig as there are many built-in operators available such as filters, joins, sorting, ordering, and so on. But you will need to face a lot of troubles if you want to perform the same operations in Hadoop.
Q-50. Mention the relational operators that are used in “Pig Latin”?
This Hadoop developer interview question asks about various relational operators used in “Pig Latin” that are SPLIT, LIMIT, CROSS, COGROUP, GROUP, STORE, DISTINCT, ORDER BY, JOIN, FILTER, FOREACH, and LOAD.
Finally, Insights
We have put our best effort to provide all the frequently asked Hadoop Interview Questions here in this article. Hadoop has successfully attracted developers and a considerable amount of enterprises. It is clearly under the spotlight and can be a great option to start a career. Again, cloud computing has already taken the place of traditional hardware infrastructures and reshaped the processes.
If you look at the leading organizations around the world, it is easily noticeable that if you want to deliver better products at a lower cost, you must incorporate cloud computing with your business. As a result, the number of jobs in this sector has increased numerously. You can expect these Hadoop Interview Questions in any cloud computing Interview. Besides, these questions can also set you apart from other interviewees and clear the fundamentals of the Apache Hadoop framework.











